How we do message processing
Our team develops a back-end system that processes messages from mobile devices. The devices collect information from complex machines and send messages to our data center. In this article I want to share our approaches to building such processing software. The ideas are quite general and can be applied to any system of the following architecture:
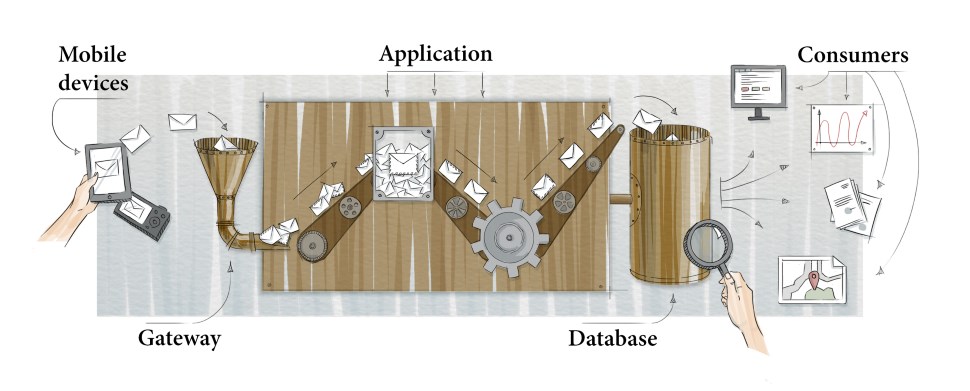
System architecture
The devices use communication channels to send messages to our gateway - the input point of our application. The application’s goal is to understand what came in, do the required actions and save the information into the database for further processing. Let’s consider the database to be the end point of processing. Sounds easy, right? But some difficulties appear with the growth of amount and diversity of incoming messages; so let’s look at some of them.
A few words on the target load level. Our system processes the messages from tens of thousands of devices, and we get from several hundreds to a thousand messages per second. If you numbers are different by orders of magnitude, it might be the case that your problems are going to look completely different and you’ll need a different set of tools to solve them.
Apart from the number of messages itself, there is a problem of irregularity and peak times. The application must be ready for relatively short peaks which might be about ten times higher than the average expectation. To address this problem we organize the system as a sequence of queues and corresponding processors.
The input gateway doesn’t do much of real job: it just receives a message from a client and puts it into the queue. This operation is very cheap, thus the gateway is capable of accepting a vast number of messages per second. Afterwards a separate process retrieves several messages - the amount it wants to get - from the queue and does the hard work. The processing happens asynchronously while the load on the system remains limited. Perhaps the time in the queue grows at peaks, but that’s it.
Normally the message processing is non-trivial and consists of several actions. Here we get to the next logical step: we break down the job into several stages, each one having a separate queue and a dedicated processor. The queues and processors are independent and may reside on separate physical servers; and we can tune and scale them independently:
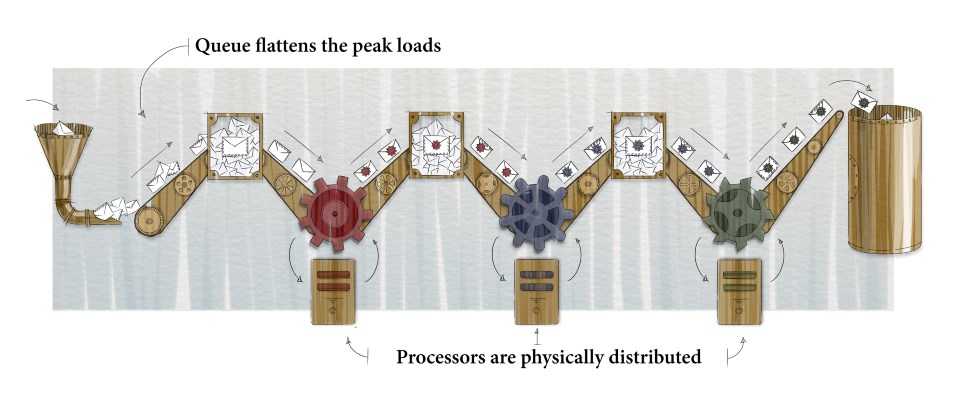
Sequence-based architecture
The first queue contains the messages from devices as-is, without decoding or transforming them. The first processor decodes them and puts them into the second queue. The second processor could, for instance, call a third-party service and enrich the message with some relevant information, and the third processor could save that information into the database.
These are the basics, so what do we still need to consider?
Define your values
-
Simplicity of creation, change and support
Asynchronous distributed message processing brings quite some extra complexity into the software product. You should constantly work on reducing this price. The code gets optimized to be, at first place, readable and straightforward for all the team members, cheap to be changed and supported. If nobody but the author can decrypt the code, no great architecture will make the team happy.
This statements looks obvious, but it might take quite some time and effort before the team starts to consistently implement this principle and not just declare it. Do the regular refactoring whenever you feel you can make the code a bit better and simpler. All the source code should get reviewed and the most critical parts are better to be developed in pair.
-
Fault tolerance
It makes sense to define your policies of hardware or subsystem failures handling from the very beginning. They will differ for different products. It might be the case that someone can throw away all the messages that come in during 5 minutes of a server reboot.
In our system we don’t want to lose messages. If a particular service is not currently available, a database call times out, or there is a random processing error, it must not result in information loss. The affected messages must be saved inside the queue and will be processed right after the problem is fixed.
Suppose your code on one server calls a web service on another server in synchronous manner. If the second server is not available, the processing will fail, and you can’t do anything but log the error. In case of asynchronous processing the message will wait for the second server to go live again.
-
Performance
Processing rate per second, latency, load on the servers - all these are important parameters of application performance. That’s why we choose the architecture to be flexible.
Although, don’t pay TOO much attention to optimization from the very beginning. Usually the majority of performance issues is created by relatively small pieces of code. Unfortunately people tend to be very bad at predicting where exactly those issues are going to appear. People write books on pre-mature optimization. So make sure that your architecture allows you to fine-tune the system and forget about optimization until the first load testing.
At the same time, and for this reason, start running the load tests early on, and then include them into your standard testing procedure. Start optimizing only when the tests reveal a specific performance problem.
Fine tune your mindset
-
Operate queues and asynchronous processors
I already described this above. Our main tools are queues and processors. While the classic approach is “get request, call remote code, wait for response, return it back to the originator”, now we should always use “get a message from a queue, process it, send a message to another queue”. The right mix of these two approaches should enable both scalability and ease of development.
-
Break the processing down into several stages
If message processing is complex enough to be split into several stages, do that by creating several queues and processors. Make sure that you don’t make it too complex to understand by unneeded fragmentation: the right balance is important. Quite often you will see a split which feels natural for developers. If not, try thinking of possible failure points. If there are multiple reasons why a processor may fail, consider its breakdown.
-
Don’t mix decoding and processing
Usually the messages arrive encoded with a protocol which can be binary, XML, JSON, etc. Decode them into your native format as soon as possible. This will help you solve two problems. First, you might need to support multiple protocols; and after decoding you unify the format of all further messages. Second, logging and debugging gets simpler.
-
Make the queues topology configurable
Structure your code in a way that allows you to change the configuration of queues relatively easy. Splitting a processor into two parts should not result in tons of refactoring. Don’t make your code depend on a specific queue mechanism implementation: tomorrow you might want to change it.
-
Do batch processing
Normally it makes sense to receive messages from a queue in batches, not one by one. The services that you use might accept arrays for faster processing and in this case one call will always be faster than a handful of small ones. One insertion of 100 rows into database is faster than 100 remote insertions.
Create tooling
-
Implement total monitoring
Invest into monitoring tools. It should be easy to see the charts of throughput, average processing time, queue size and time since last message with breakdown by queue.
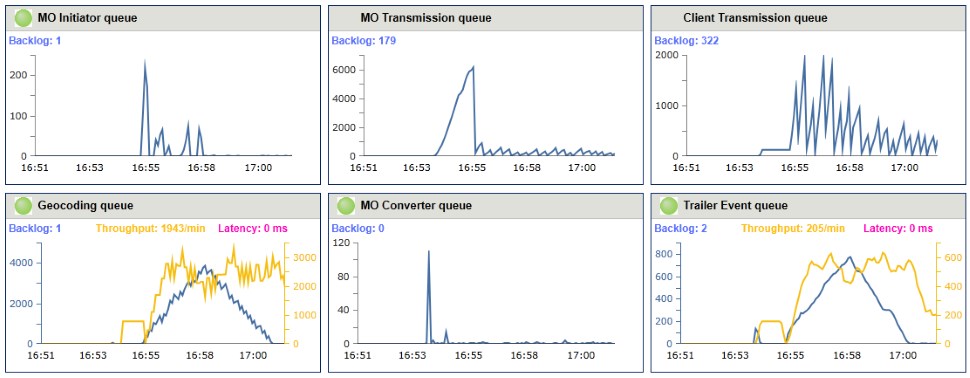
We use monitoring tools not only on production and staging environments but also on testing servers and even developer’s machines. Carefully baked charts are helpful during debug and load testing procedures.
-
Test everything
Message processing systems are perfect fields to apply fully automated testing. Input data protocols are well-defined and there is no human interaction. Cover your code with unit tests. Make your queues pluggable so that you could mock your real queues out with test in-memory queues to run quick intercommunication tests. Finally, create full-blown integration tests which should be run on staging environment (and preferably also on production).
-
Store the failed messages
Usually you don’t want one erroneous message to stop the complete queue processing. Being able to diagnose the problem is equally important. So put all the failed messages into a specialized storage and put a spotlight on it. Make a tool to move messages back to the relevant queue as soon as the failure reason is addressed.
Same or similar mechanism can be used to store the messages to be processed at some point of time in the future. Keep them in that special storage and check periodically if now is time to proceed.
-
Automate the deployment
Application setup and update must require just one or two clicks. Strive for frequent updates on production; ideally - automated deployment on every commit to the dedicated branch. Deployment scripts or tools will help developers maintain their personal and testing environments up-to-date.
Wrapping up
Clean and understandable architecture provides developers with a good means of communication, helps figure out the similar vision and concepts. Architecture metaphor expressed in form of a picture or short document will bring you closer to smart design, will help find errors or plan a refactoring.
Happy message processing!
