Azure Functions Get More Scalable and Elastic
Back in August this year, I’ve posted Azure Functions: Are They Really Infinitely Scalable and Elastic? with two experiments about Azure Function App auto scaling. I ran a simple CPU-bound function based on Bcrypt hashing, and measured how well Azure was running my Function under load.
The results were rather pessimistic. Functions were scaling up to many instances, but there were significant delays in doing so, so the processing slowed down up to 40 minutes.
Azure Functions team notified me that they rolled out an updated version of the service, which should significantly improve my results.
So I ran the exact same tests again, and got the new results. I will show these results below.
TL;DR. Scaling responsiveness improved significantly. The max delay reduced from 40 to 6 minutes. There are some improvements still to be desired: sub-minute latency is not yet reachable for similar scenarios.
Setup
See the Function code and the description of the two experiments in my previous article.
Experiment 1: Steady Load
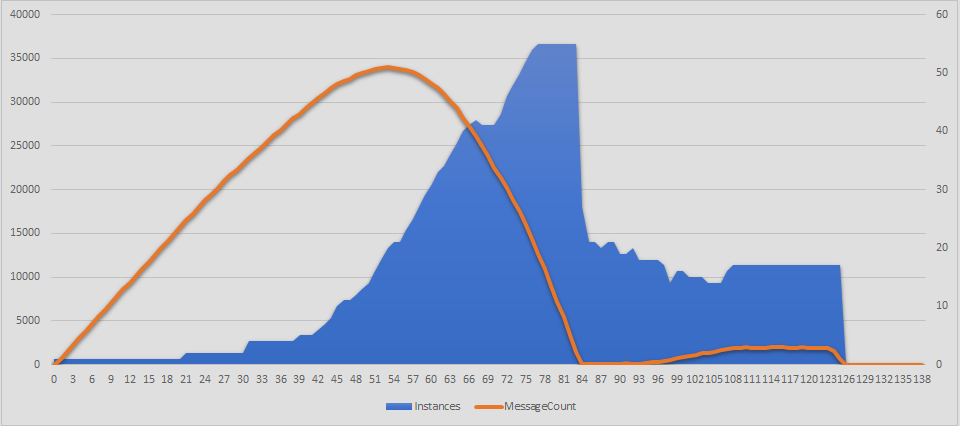
In “Steady Load” scenario 100,000 messages were sent to the queue at constant pace, evenly spread over 2 hours.
Here are the old metrics of Queue Backlog and Instance Count over time:
Old charts are shown in gray background
You can see a huge delay of almost one hour before the function caught up to speed of incoming messages and half-an-hour more before the backlog got cleared.
The new results on the same chart after the runtime update:
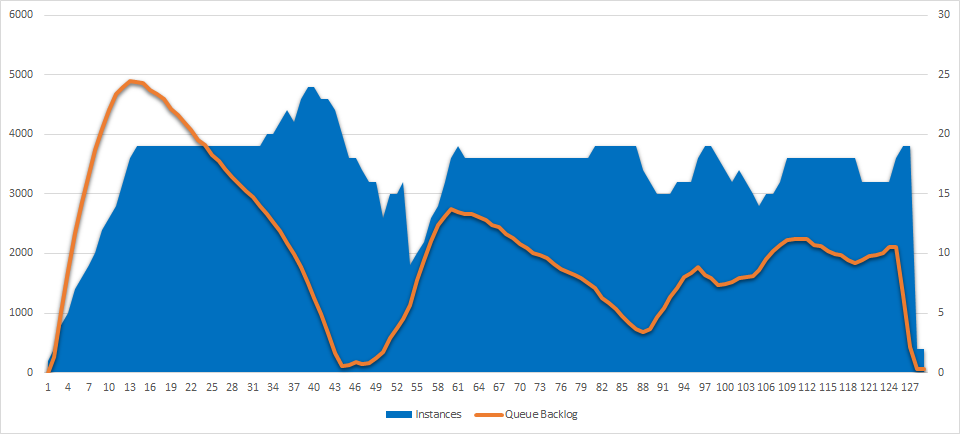
This looks much better. The maximum backlog is 7 times lower; there’s almost no initial delay before the auto scaling kicks in; and overall instance allocation is much more stable.
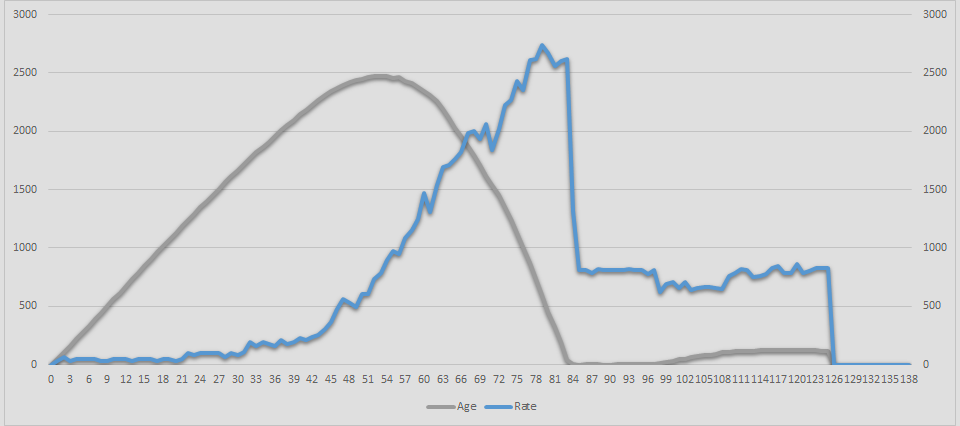
One more chart is from the same experiment, but it shows slightly different metrics. The old results of Delay (Age) in seconds and Processing Rate in messages per minute:
The new chart after the runtime update:
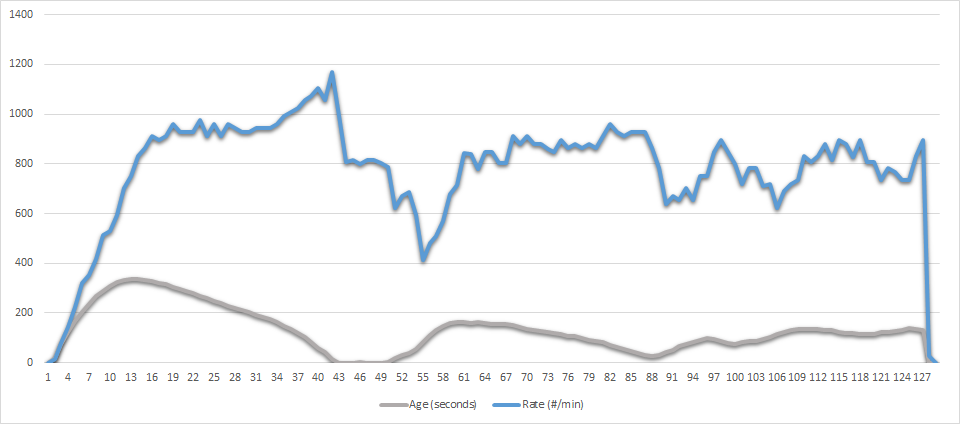
Again, much less delay overall, and processing rate more-or-less stabilizes after the first 15 minutes.
Experiment 2: Spiky Load
The second experiment spanned over 5 hours. The messages were sent mostly at low-ish fixed rate, except for 5 periods of sudden spikes. The green line on the charts below shows these spikes very well.
At the first run 4 months ago, Functions runtime had troubles keeping up to speed even between those bursts of messages.
Here is the chart of the old spiky load processing:
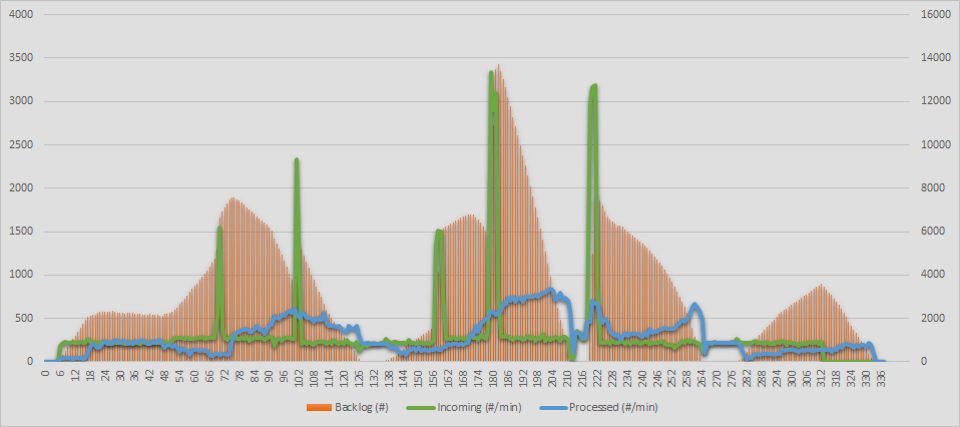
You can see that the backlog after each spike goes down really slow. The blue line of processing rate doesn’t match the green line almost nowhere, which reveals the struggle to adapt.
The new results of the same chart after the runtime update are quite different:
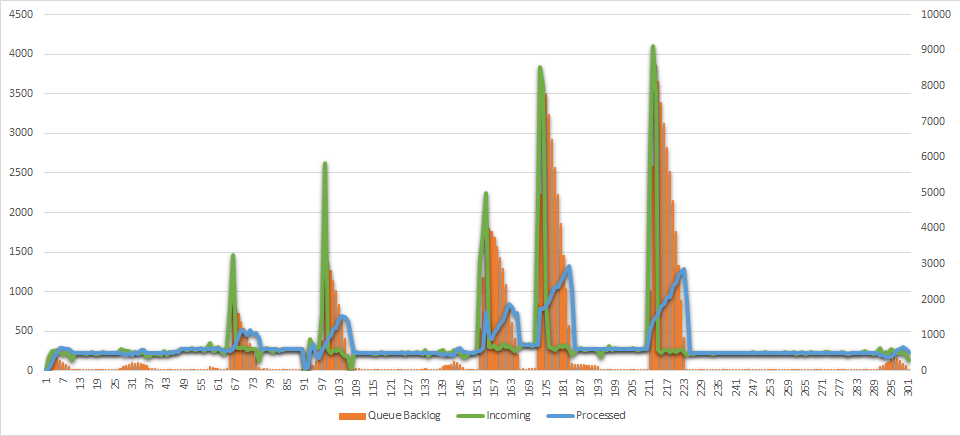
Notice how the backlog is empty and the blue processing rate matches exactly the incoming rate during all time except after traffic bursts. The queue goes up during each spike, but the processing rate immediately accelerates too, and the crisis is gone within 15 minutes.
Conclusions
Azure Functions team is clearly working on improvements. While the results in August were puzzling or even embarrassing, the December benchmark makes much more sense.
Looks like Azure Functions are now suitable for CPU-intensive data processing scenarios with flexible load, targeting the maximum delay at about several minutes.
Obviously, the results are not perfect just yet. Here’s what still can be done better:
-
Scale faster initially. In the first experiment, the biggest delay appeared right after the start, when the backlog was growing linearly for 10 minutes. “0 to 100” might not be a very realistic scenario, but probably that’s how many folks will test Functions against their workloads.
-
Do not scale down that fast after backlog goes to 0. Every time the queue backlog goes to 0, the runtime kills the biggest part of instances almost immediately. During my runs, this caused the queue to grow again without a good reason from user’s perspective.
-
Do not allow the backlog to grow without message spikes. Related to the previous item, but slightly different focus. When the load is stable, I would expect the runtime to keep my queue as close to empty as possible. I guess Azure tries to minimize the resources that it consumes behind the scenes, but this should be balanced in favor of user experience.
-
Make scaling algorithms more open. It’s a black box right now. I would love to see some documentation, if not code, to be published about what exactly to expect from Consumption Plan auto scaling.
I’ll be running more scaling experiments with other types of workloads in the nearest future, so… more benchmarks are coming.
Happy scaling!
