Concurrency and Isolation in Serverless Functions

Serverless vendors have different approaches when it comes to sharing or isolating resources between multiple executions of the same cloud function. In this article, I’ll explore the execution concurrency models of three FaaS offerings and the associated trade-offs.
AWS Lambda
AWS Lambda executions are always entirely isolated from each other. Simple enough, right?
A function execution maps 1:1 to a function instance. Each execution runs on a separate host, i.e., a dedicated container with its own instance of the runtime. All the resources of this host (CPU, RAM, scratch disk space) are dedicated solely to this execution.
AWS Lambda spins up as many hosts as needed to process all concurrent requests:
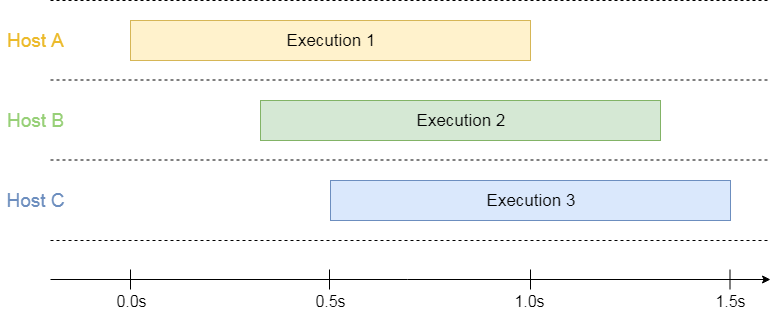
3 overlapping executions running on 3 isolated hosts
This model has a benefit of predictability: The resource manager allocates the same amount of resources to each execution. Therefore, the variability between executions is low (with the cold start being a remarkable exception).
Resource allocation has to be preconfigured by selecting the memory limit. CPU cycles are allocated proportionally to RAM. Performance variation might increase for smaller instance sizes: 128 MB instances are empirically known to be less consistent.
In terms of pricing, the executions are independent. The bill consists of two parts: a fixed fee per execution and a variable charge for execution duration, measured in GB-seconds:
<allocated instance size in GB> * <duration of execution rounded up to 100ms>
In the example above, if each execution has 1 GB of allocated RAM and runs for 1 second, the total bill will be 3 GB-seconds.
This model works but is definitely better for some workloads than others.
I/O Bound Workloads
Typically, enterprise workloads are not very demanding to CPU (not much computation other than serialization and conversions) and RAM (mostly consumed by the runtime and libraries since functions are stateless). Many functions end up calling other resources synchronously over the network: managed cloud services, databases, and web APIs. This means the execution duration is mainly determined by the response time of those resources.
AWS would charge for the full execution time, even if 90% of the time were spent waiting for an external response. In this case, the resources dedicated to the execution are basically wasted.
Ben Kehoe argued for the need for asynchronous FaaS call chains in serverless systems almost 2 years ago, but, unfortunately, the situation is still the same.
Resource Pooling
In the ideal world of greenfield projects, serverless functions would only be purely transforming inputs to outputs or would make external calls that respond fast and don’t require keeping any state between the requests.
However, in the real world, you’re often required to access traditional SQL databases, such as Postgres or SQL Server. Database connection protocols were not designed for today’s serverless services with hundreds of stateless short-lived single-execution hosts. Connections are expensive to establish. There is a limit of how many of them the database can handle. Therefore, the client should strive to reuse the connections as much as possible.
Good examples of these issues and possible workarounds are shown in these great posts by Jeremy Daly:
- How To: Reuse Database Connections in AWS Lambda
- How To: Manage RDS Connections from AWS Lambda Serverless Functions
- Serverless MySQL.
A smaller scale version of the same problem applies to HTTP-based communication: reuse of DNS lookups, TCP connections, etc.
Obviously, it would help if multiple executions of a function shared the pool of database and TCP connections.
Azure Functions
Azure Functions tried to address this issue by separating the notion of executions and instances. In the Azure world, an instance is a host with dedicated resources (both CPU and RAM allocations are fixed and not currently configurable). Each instance is then capable of running multiple executions at the same time and reusing the resources for all of them.
If we apply the Azure model to the example of the 3 overlapping executions we discussed in the AWS section, we can quickly see how they differ:
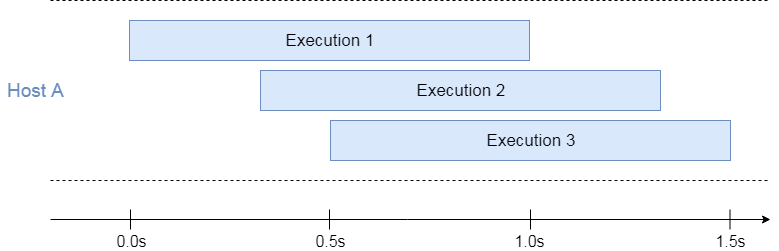
3 overlapping executions running on a single host
In this case, the executions share the common pool of resources by running at the same host.
The potential efficiency is also reflected in the reduced bill: You’re charged for a merged window of the parallel invocations. If 1 GB of memory is consumed (regardless if 1, 2, or 3 executions are active), then the total bill for 3 executions is 1.5 GB-seconds, where 1.5s is the time between the start of the first execution and the end of the last execution. That’s 2x cheaper compared to AWS Lambda.
This calculation might not be accurate for very short executions or many concurrent executions. The minimum time charge is always 100 ms, and 0.125 GB is the minimum memory charge. For that reason, a single execution can’t be less than 0.0125 GB-seconds.
In the example above, sharing resources is lean and beneficial to the end customer. However, it might be problematic in the case of CPU-bound workloads; see Bcrypt/Azure example in How Serverless Providers Scale Queue Processing.
Another benefit of concurrent executions is the potential for reuse of SQL connection pools and HTTP clients. For instance, an Azure Function implemented in C# shares the same .NET process for concurrent executions. Therefore, any static objects are reused automatically.
Configuring Concurrency in Azure Functions
We have now established a clear trade-off between resource allocation efficiency and performance guarantees. Now that we understand the basics of concurrent executions, you might be wondering how Azure Functions decide how many executions to put into a single instance.
The truth is, there isn’t one clear answer. It’s a combination of decisions made by the Scale Controller and configuration knobs. It also depends on the type of the event triggering the execution.
For Azure Functions that are triggered by queue messages, there are settings batchSize and newBatchThreshold. The maximum number of concurrent executions is then derived from the simple equation batchSize + newBatchThreshold.
Cosmos DB and Event Hubs triggers invoke one function execution per batch of items. Each batch is tied to one partition in the event source. The concurrency is then determined at runtime by the Scale Controller based on factors, such as the number of partitions and the metrics reported from existing instances.
HTTP Functions are the marriage of these two approaches. There is a setting, maxConcurrentRequests, that can be used to limit the concurrency explicitly. It defaults to 200 concurrent requests, which is quite generous. In practice, it’s not likely to reach that level of execution concurrency unless they are idle for minutes. Most commonly, the Scale Controller creates new instances of the function before the maximum limit is exhausted, which may improve the response time but will incur a higher bill.
Binaris
Binaris has support for both modes: AWS Lambda-esque exclusive invocations or concurrent invocations similar to Azure Functions. The user decides which one to use by changing a simple setting in the binaris.yml file:
functions:
NewCreate:
file: function.js
entrypoint: handler
executionModel: concurrent
runtime: node8
When executionModel is set to exclusive, the Binaris runtime limits the concurrency of each “function unit” (container) to one.
Alternatively, when executionModel is set to concurrent, Binaris enables the shared execution model, which allows for re-entrant invocations on the same function unit. The current model allows for up to 10 concurrent invocations within a single unit (the number will be configurable in the future). All re-entrant invocations share the same memory, disk space, and available vCPU.
Binaris charges a flat rate for each millisecond of running time. The rate does not depend on whether a single execution is running or if there are multiple executions running on the same instance.
There is no configuration for instance CPU or RAM allocation. The price of 1 second of execution is equivalent to what AWS charges for 1 GB instances. In the example above, the customer is charged for 1.5 seconds of execution time.
The granularity is always 1 ms, and there is no minimum charge, which may make a big difference for short executions compared to the minimum of 100 ms for AWS and Azure. This makes Binaris very competitive for quick functions: If 10 parallel executions complete within 10 ms, the total charge is 100 times less compared to AWS Lambda.
Conclusion
Sharing compute resources between concurrent executions of serverless functions can be beneficial for I/O-bound workloads. During the periods when some executions are idle waiting for a response from the network, other executions may continue to use the allocated resources. This shareability also applies to assets, such as database connections and libraries loaded into the instance’s memory.
The shared execution model allows for more efficient use of hardware resources, which, in turn, leads to a lower bill.
However, concurrency can also lead to resource contention for CPU-intensive workloads, which might negatively affect the performance of serverless functions. Thus, until cloud providers come up with a perfect method of optimizing concurrency at runtime, it’s essential to give the function owner control over the concurrency mode. Given a simple knob, they can make a judgment call between concurrency and isolation.

Responses