Provisioned Concurrency: Avoiding Cold Starts in AWS Lambda
AWS recently announced the launch of Provisioned Concurrency, a new feature of AWS Lambda that intends to solve the problem of cold starts. In this article, we take another look at the problem of latency-critical serverless applications, and how the new feature impacts the status-quo.
Concurrency Model of AWS Lambda
Despite being serverless, AWS Lambda uses lightweight containers to process incoming requests. Every container, or worker, can process only a single request at any given time.
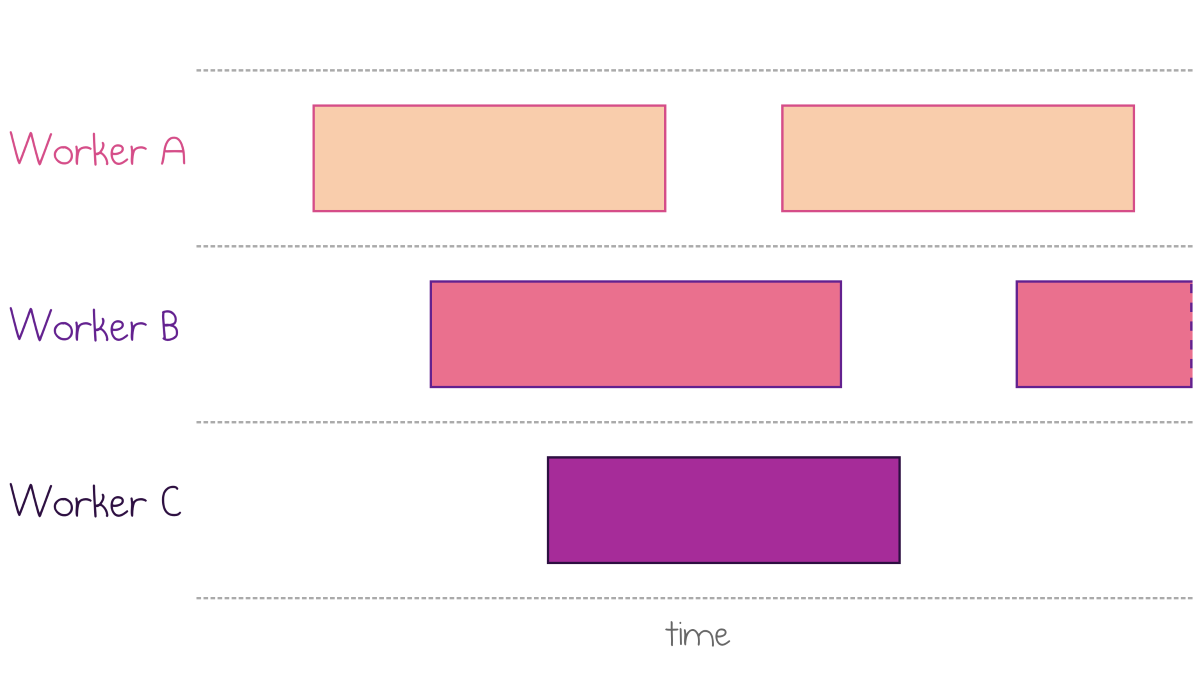
Overlapping executions land on separate workers
Because of this, the number of concurrent requests defines the number of required workers that a specific AWS Lambda function needs to serve a response at any given moment.
Cold Starts
How does AWS know how many workers it needs to run for a given function? Well, it doesn’t know in advance. AWS allocates new workers on-demand as the Lambda gets invoked.
Whenever Lambda receives a request but it has no idle workers, the control plane assigns a new generic worker to it. The worker then has to download the custom code or binaries of your Lambda and load them into memory before it can service the request. This process takes time, which significantly increases response latency.
The issue of sporadically slow responses caused by the need to increase the pool of workers is known as Cold Start. Cold starts are consistently the top concern about the applicability of serverless technologies to latency-sensitive workloads. There are numerous articles about the problem, including many articles I have written in the Cold Starts section on my website
Warming
Cold starts don’t occur for the majority of requests because AWS Lambda reuses workers between subsequent invocations. However, if a particular worker is idle for too long (usually, several minutes), AWS may decide to recycle and return it to the generic pool.
A trick known as Lambda Warmers uses kept-alive workers to reduce the frequency of cold starts. The idea is to have a CloudWatch timer that fires every few minutes and sends N parallel requests to the target Lambda. If all those requests land at the same time, AWS has to provision at least N workers to process them. The actual operation doesn’t have to do any useful work, but it resets the recycling timer back to zero.
There are a few drawbacks with this approach:
- If a valid request comes at the same time as warming requests, it might hit a cold start.
- Extra logic is needed in the Lambda code to detect warming requests and short-circuit them instead of doing useful work.
- CloudWatch rules require additional setup and management.
- The result is still best-effort: Lambda still recycles workers from time to time.
You can find more details about how Pulumi can help with some of these issues in AWS Lambda Warmer as Pulumi Component.
Provisioned Concurrency
At re:Invent 2019, AWS introduced Lambda Provisioned Concurrency—a feature to work around cold starts. The base concurrency model doesn’t change. However, you can request a given number of workers to be always-warm and dedicated to a specific Lambda.
Here is an example of configuring the provisioned concurrency with Pulumi in TypeScript:
const lambda = new aws.lambda.Function("mylambda", {
code: new pulumi.asset.FileArchive("./app"),
handler: "handler",
role: role.arn,
publish: true,
});
const fixed = new aws.lambda.ProvisionedConcurrencyConfig("fixed-concurrency", {
functionName: lambda.name,
qualifier: lambda.version,
provisionedConcurrentExecutions: 2,
});
The snippet sets the provisioned concurrency for mylambda to a fixed value of 2. Note that concurrency is provisioned per Lambda version, and it can’t be set for the $LATEST version alias. Therefore, I set the publish attribute of my Lambda to true and reference a specific version of the Lambda in provisioning.
Dynamic Provisioned Concurrency
A fixed level of provisioned concurrency works well for stable workloads.
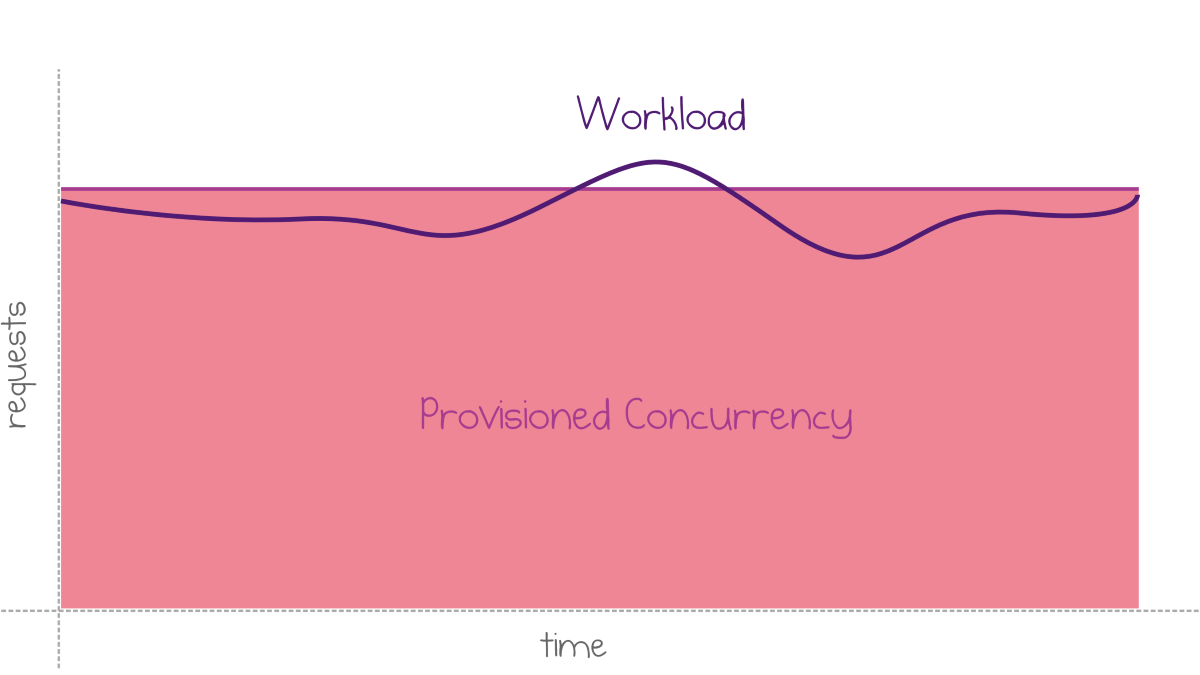
Fixed provisioned concurrency for uniform workloads
However, many workloads fluctuate a lot. Extreme elasticity and lack of configuration parameters have always been the essential benefits of AWS Lambda. It works great if you can tolerate the cold starts that come during scale-out. If not, you can explore more advanced scenarios for provisioning concurrency dynamically.
Instead of choosing a permanently fixed value, you can configure provisioned concurrency to autoscale. The first required component is the autoscaling target:
const resourceId = pulumi.interpolate`function:${lambda.name}:${lambda.version}`;
const target = new aws.appautoscaling.Target("target", {
resourceId,
serviceNamespace: "lambda",
scalableDimension: "lambda:function:ProvisionedConcurrency",
minCapacity: 1,
maxCapacity: 10,
});
The second component is the autoscaling policy, which defines the conditions when scaling starts. There are two important ways to adapt your concurrency provisioning to traffic patterns.
Scheduled profile
Quite often, increases in request rates are partially predictable. For example, usage increases during business hours and decreases at night.
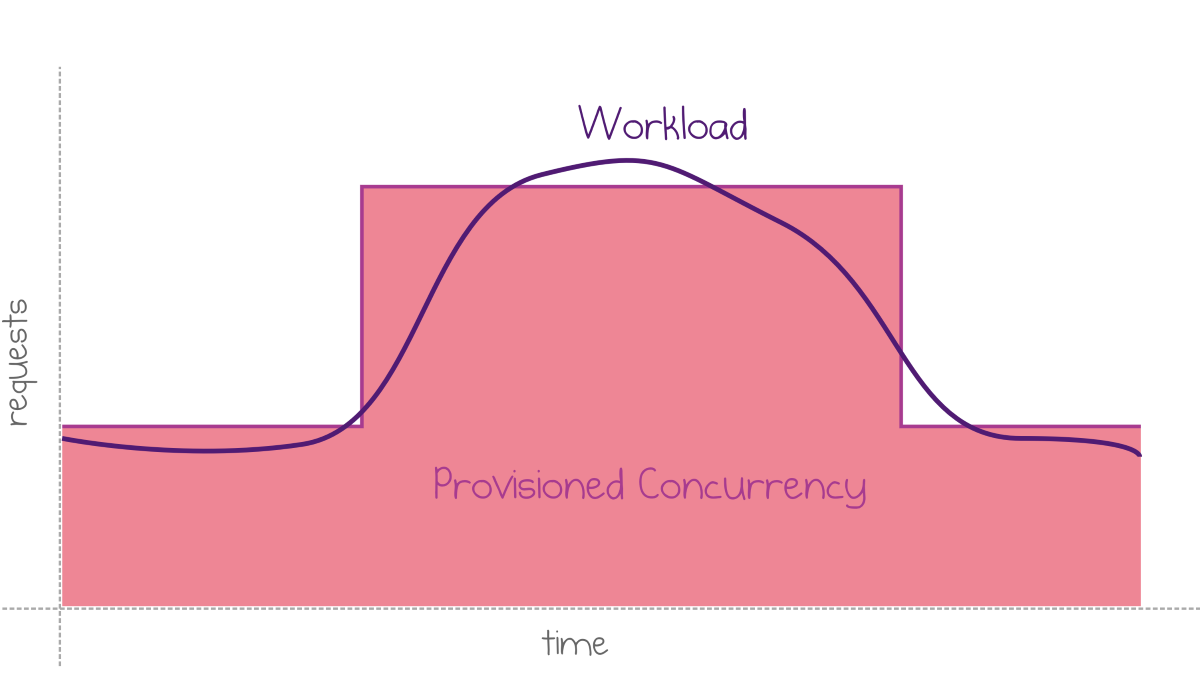
Provisioned concurrency matches predictable workload changes
The following snippet sets two scheduled rules that switch between two levels of provisioned concurrency every day.
function scheduledConcurrency(name: string, cron: string, capacity: number) {
return new aws.appautoscaling.ScheduledAction(`schedule-${name}`, {
resourceId,
serviceNamespace: "lambda",
scalableDimension: "lambda:function:ProvisionedConcurrency",
scalableTargetAction: {
minCapacity: capacity,
maxCapacity: capacity,
},
schedule: `cron(${cron})`,
}, { dependsOn: [target]});
}
scheduledConcurrency("day", "0 8 * * ? *", 10);
scheduledConcurrency("night", "0 18 * * ? *", 2);
The example defines a helper function and calls it twice to set two schedules with different parameters.
Autoscaling based on utilization
If your workload pattern is less predictable, you can configure autoscaling for provisioned concurrency based on the measured utilization.
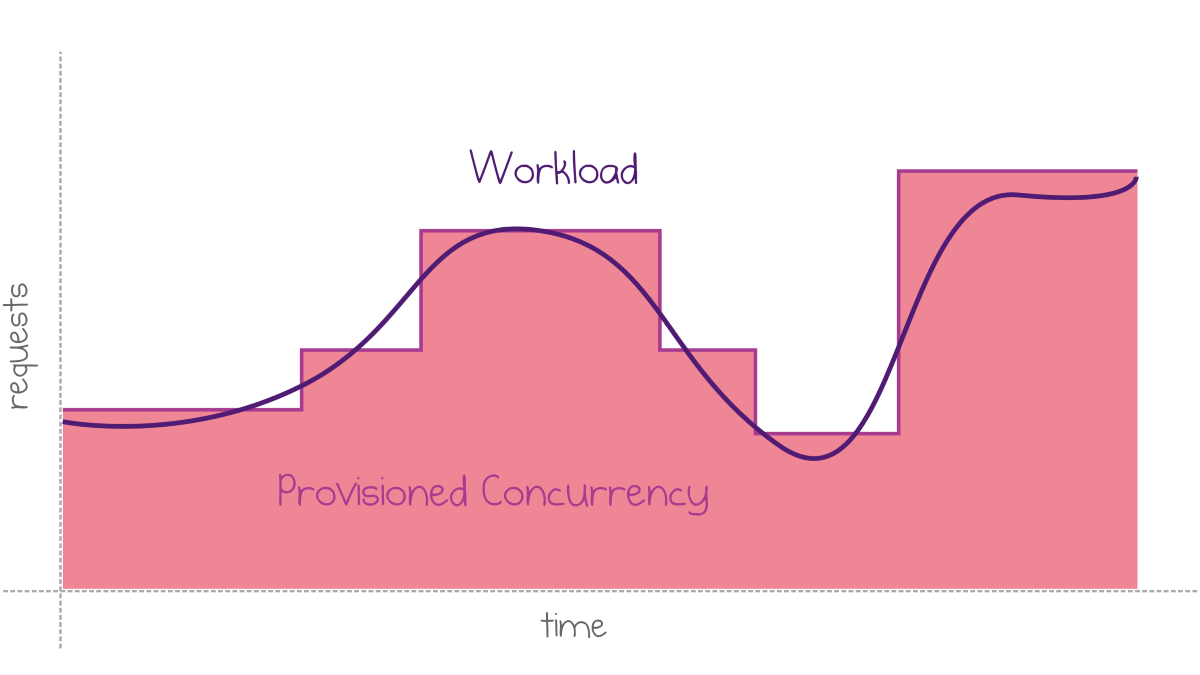
Provisioned concurrency matches the variation in workload
Here is a basic example of a dynamic scaling policy.
const scaledConcurrency = new aws.appautoscaling.Policy("autoscaling", {
resourceId,
serviceNamespace: "lambda",
scalableDimension: "lambda:function:ProvisionedConcurrency",
policyType: "TargetTrackingScaling",
targetTrackingScalingPolicyConfiguration: {
targetValue: 0.8,
predefinedMetricSpecification: {
predefinedMetricType: "LambdaProvisionedConcurrencyUtilization",
},
},
}, { dependsOn: [target]});
Currently, there are issues with autoscaling based on the metrics, which makes provisioned concurrency scale less effectively than what the chart above shows. Hopefully, Amazon will fix these issues soon.
Pricing
While hand-crafted Lambda warmers are virtually free, provisioned concurrency can be costly. The new pricing is an integral part of the change: Instead of purely per-call model, AWS charges per hour for provisioned capacity.
You would pay $0.015 per hour per GB of provisioned worker memory, even if a worker handled zero requests.
The per-invocation price gets a discount: $0.035 per GB-hour instead of the regular $0.06 per GB-hour. This change means that fully-utilized workers would be cheaper if provisioned compared to on-demand workers.
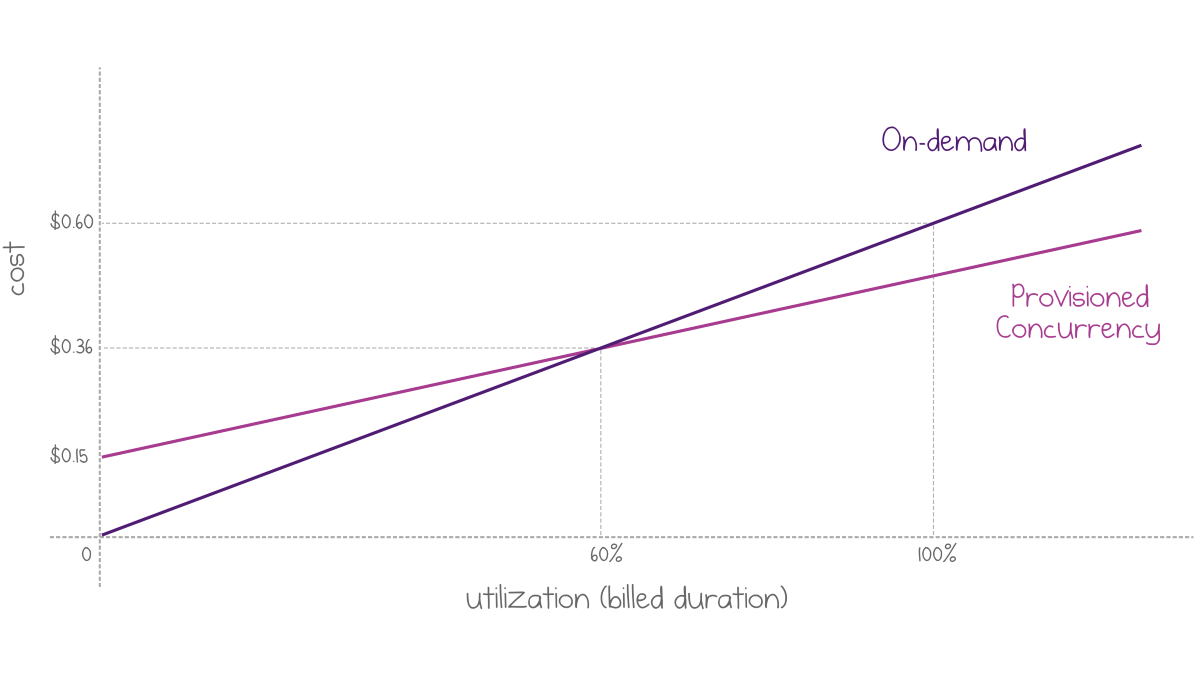
Comparison of the cost of a 1GB worker for two billing models
The equilibrium point is at 60% utilization. Note that because the billed duration is rounded up to the nearest 100 ms for each execution, the utilization is not limited to 100%. A series of sequential executions can be processed by a single worker. If each execution is 10 ms, the charge is still 100 ms, and the total utilization can be as high as 1000% in terms of the chart above!
Finally, be careful to clean up your resources after any experiments: Leaving running workers with provisioned concurrency can be expensive! Using pulumi destroy removes resources after you finish experimenting.
Conclusion
Provisioned concurrency brings the long-awaited solution to cold starts in AWS Lambda. However, it comes at a cost in terms of a direct impact on billing and management overhead to provision concurrency at optimal levels.
For high-load functions where utilization is continuously above a known level of requests, it makes sense to set the provisioned concurrency to that level to save money and have the guarantee of warm workers.
If your Lambda hosts a latency-sensitive API, especially with runtimes like Java and .NET, you should strive to find the right balance between the percentage of requests that result in a cold start and the money spent on concurrency. Autoscaling should help once AWS has fixed the initial glitches that slipped into their current services.
If you want to try this for yourself, we’ve updated the Serverless App example to show off the scenario of configurable AWS Lambda provisioned concurrency.

Responses