Eliminate Cold Starts by Predicting Invocations of Serverless Functions
Developers and decision-makers often mention cold starts as a significant drawback of serverless functions. Cloud providers continually invest in reducing the latency of a cold start, but they haven’t done much to prevent them altogether. The most common technique is to keep a worker alive for 10-20 minutes after each request, hoping that another request comes in and benefits from the warm instance.
This simple strategy works to some extent, but it’s both wasteful in terms of resource utilization and not particularly helpful for low-usage applications. Is there an alternative strategy that could adapt to the workload, reduce the frequency of cold starts, and be more efficient?
In Azure Functions Production Usage Statistics, I reviewed the first part of the Serverless in the Wild paper, which outlines statistics of Azure Functions running in production. Actually, the ultimate goal of that paper is to suggest an improvement to the cold start mitigation policy and validate the proposed strategy based on the data.
This article is my second installment of the paper review. I focus on the idea of predicting future invocations and pre-warming of serverless workers. I describe the current state of cold starts, then explain the suggested improvements from the paper. Finally, I present my own take on those ideas.
The new policy is definitely worth studying because it will be applied to your Azure Functions soon!
Challenges
As the statistics show, many Azure Function Apps are called very infrequently. Let’s consider a concrete example: an HTTP-triggered function that runs approximately once per hour and returns current data for a report.
Currently, every invocation of such a function would hit a cold start. Specifically, Azure uses a fixed “keep-alive” policy that retains the resources in memory for 20 minutes after execution. This isn’t helpful in our scenario since requests come every 60 minutes.
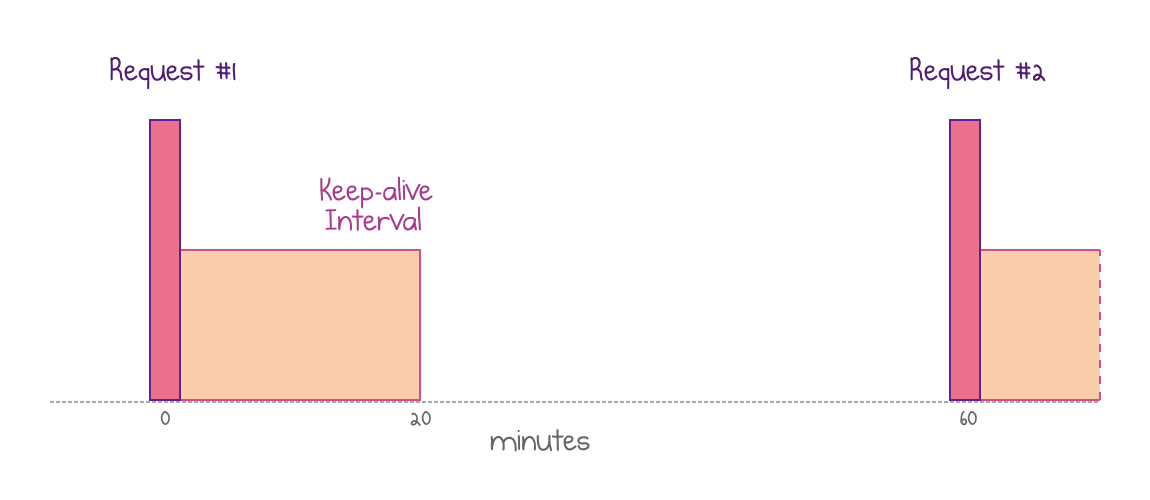
Warm instances are recycled after 20 minutes, so an hourly request hits a cold start
In this specific case, the fixed policy is problematic for everyone:
- Users hit a cold start every time, which significantly increases the response time.
- Azure wastes resources on keeping a warm instance in memory for 20 minutes every hour without any benefits.
Indeed, cloud providers seek to achieve high function performance at the lowest possible resource cost. They can’t keep all functions in memory all the time: as the stats show, most functions run very seldom, so keeping all of them warm would be a massive waste of resources.
What if the cloud provider could observe each application and adapt the policy for each application workload according to its actual invocation frequency and pattern?
Optimal Strategy Predicts The Future
Let’s start with a hypothetical ideal solution for our specific one-call-per-hour example. Instead of keeping a warm instance for a fixed period after each invocation, an efficient policy would shut down the instance immediately after each execution. Then, it would boot a new instance right before the next invocation is about to come in.

A new instance is pre-warmed right before the request comes in and recycled immediately after the execution is complete
This solves both problems above. Now, all requests are served quickly because Azure creates a fresh instance before a request comes in. Also, Azure saves resources because it can pre-warm the instance shortly before each request and shut it down immediately after the invocation is completed.
This ideal case only works in the world of perfect information. Of course, Azure can’t perfectly predict the future and spin up a new instance right before the next HTTP request. Instead, it would need to learn the workload and try to predict the next invocation probabilistically. That’s the essence of the policy that the authors of “Serverless in the Wild” suggest.
Predicting arbitrary workloads can be pretty hard. Every application is unique, and invocations are caused by external events like human behavior or actions in business processes.
Also, there are limits to resources that a prediction policy may consume. The policy calculation should be efficient and not have a significant impact on the system’s overall performance. A practical policy would have low overhead both in terms of the size of data structures and the CPU usage overhead.
Proposed Policy
The paper suggests a practical policy that tries to predict future invocations without being too expensive.
Let’s start at the point when a new application has just been deployed. Azure knows nothing about its invocation patterns yet. The new policy would default to the traditional fixed “keep-alive” interval but would keep an instance running for a generous 4 hours. Simultaneously, it starts learning the workload.
Every time a new request comes in, the policy calculates how many minutes passed since the end of the previous invocation and records this value in a histogram. The histogram’s bins have one-minute granularity. So, in my example, if an invocation came 60 minutes after the previous one, the value for the bin 60 will increase by one.
At some point, the policy would decide that it knows enough to start predicting future invocations. The histogram for my application may look like this:
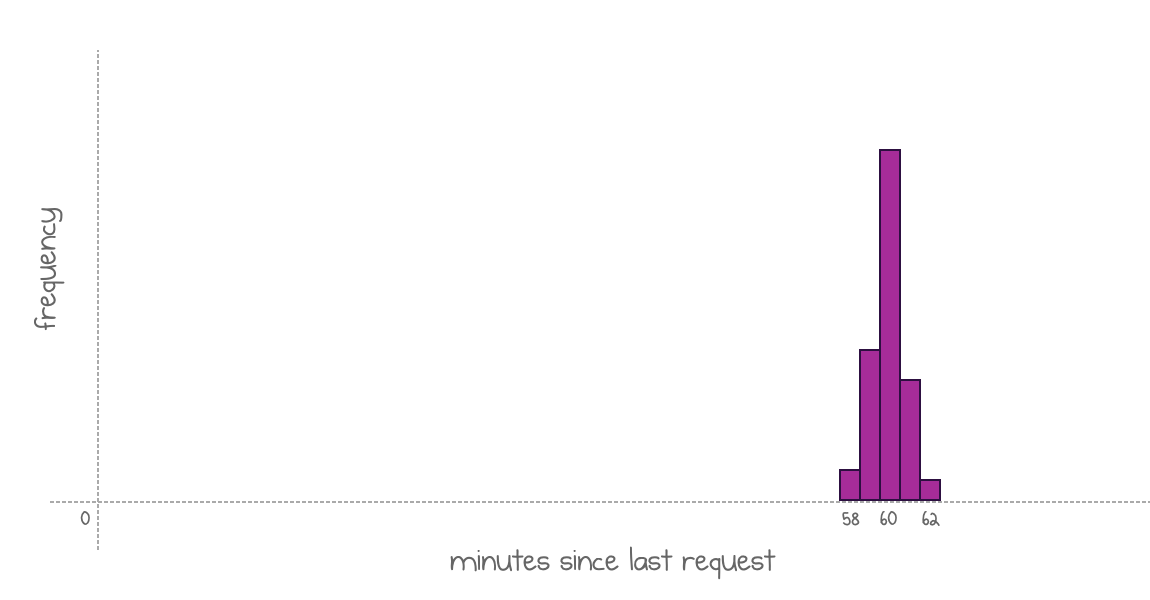
Every column shows how many requests landed on minute X after a previous execution
The new adaptive policy kicks in. Now, it shuts down the active instance after each request, because it knows that the next invocation is unlikely to come any time soon. Then, it uses two cut-off points to plan the warming strategy:
- The head cut-off point is when a new warm instance should be ready. Calculated as 5th percentile minus 10% margin. Approximately 53 minutes in my example.
- The tail cut-off point is when to kill the warm instance if no request comes in. Calculated as 95th percentile plus 10% margin. Approximately 67 minutes in my example.
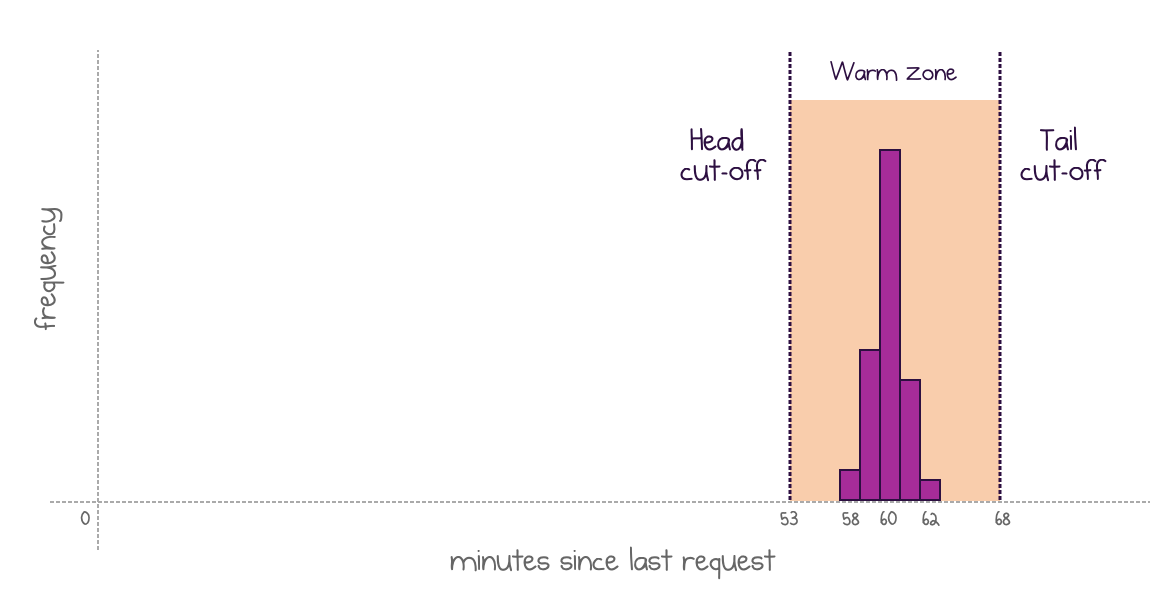
An adaptive policy pre-warms an instance at the head cut-off and keeps it until a request comes or until the tail cut-off
Because my specific workload is highly predictable, it would enjoy the absence of cold starts. Would the policy work for other scenarios?
Scenarios
The suggested policy makes sense for the example we considered so far. However, real-life workloads are very diverse. Let’s try to generalize and consider several possible scenarios and how the policy handles them.
Regular cadence
Consistent intervals between invocations are the ideal match for the suggested policy. If a histogram is well-shaped and relatively narrow, both head and tail cut-offs are easy to identify. These distributions produce the ideal situation: long shutdown periods and short keep-alive windows.
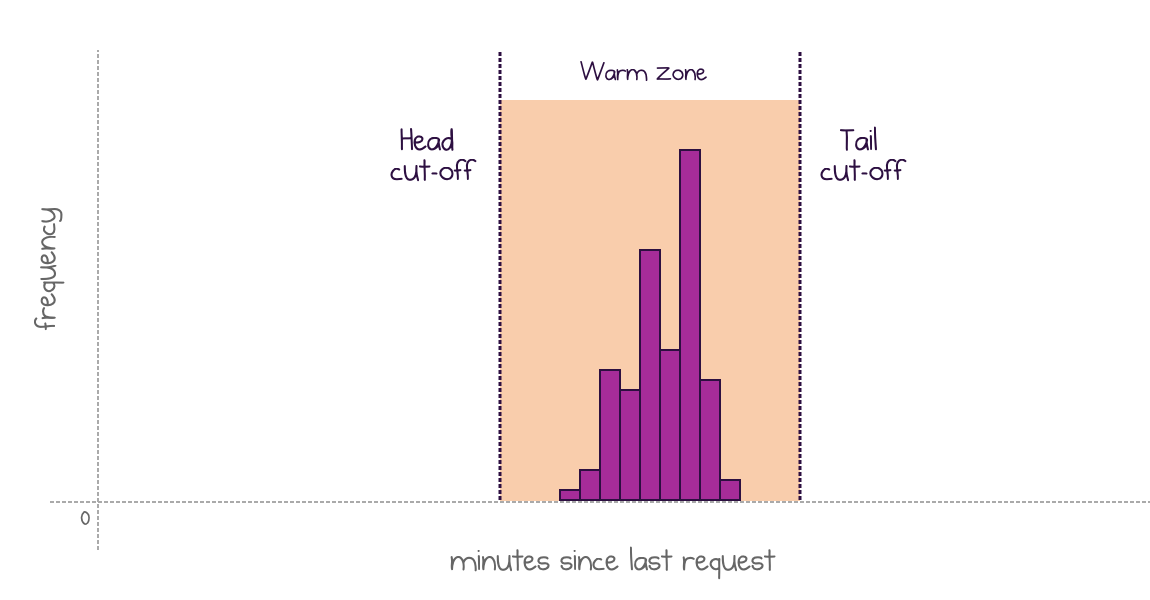
Well-shaped narrow distribution produces clear cut-off points
My example above falls into this category.
Frequent invocations
Many applications would invoke functions frequently, so, many measured intervals would be close to zero.
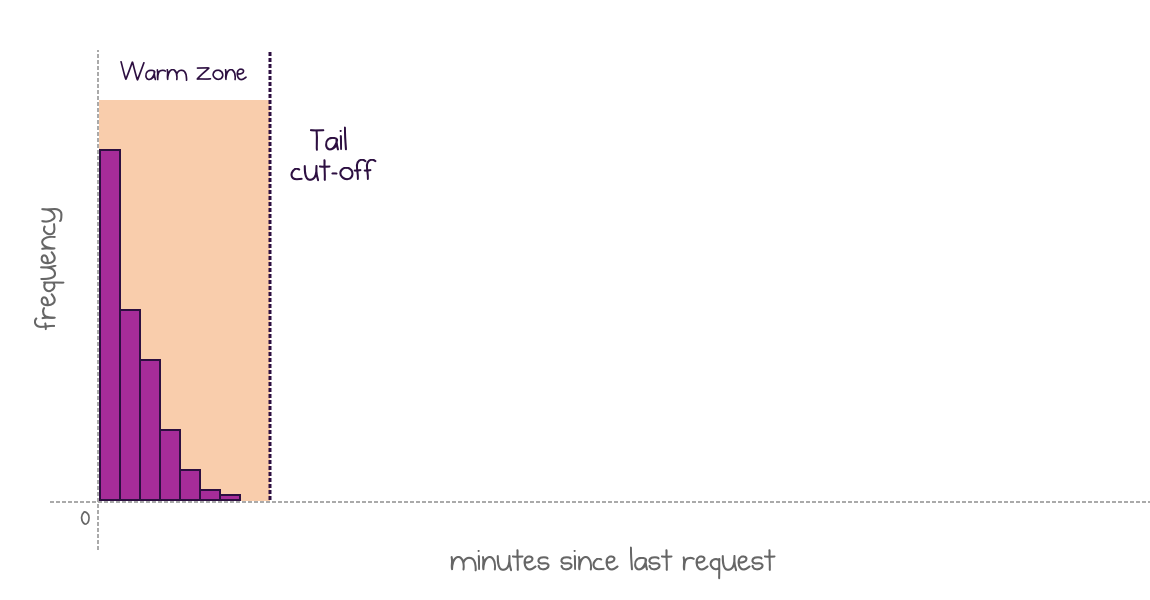
In this case, instances are not unloaded after a request is executed and wait for another one, or the tail cut-off moment
In these cases, the head cut-off is rounded down to zero. The policy does not shut down the application after a function execution but keeps it alive until the next execution, or until the tail cut-off.
Inconsistent invocations or not enough data
The policy needs a certain amount of quality data to start being useful in predicting the next invocation. The application may be recently deployed and may not have enough points yet:

Too few data to make reliable predictions: wait and learn while using the default policy
Alternatively, data points might not come in a well-shaped cluster:
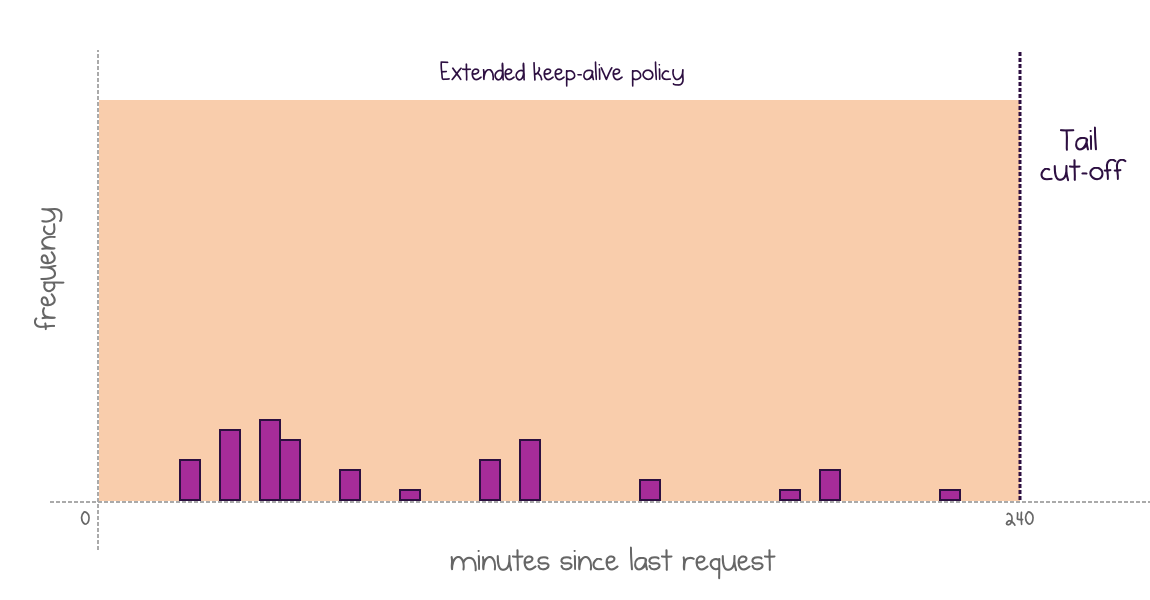
No definite shape of the histogram: fall back to the default policy
In both of these cases, the policy reverts to a default approach: no shutdown and a long keep-alive window. This puts an extra burden on the cloud provider, but the idea is that these scenarios would be rare enough to allow the policy to stay practical.
Invocations beyond 4 hours
The policy defines a maximum value for histogram data to limit the storage capacity for the histogram. The paper suggests a maximum of 4 hours. All intervals beyond that threshold are recorded in a special overflow bin.
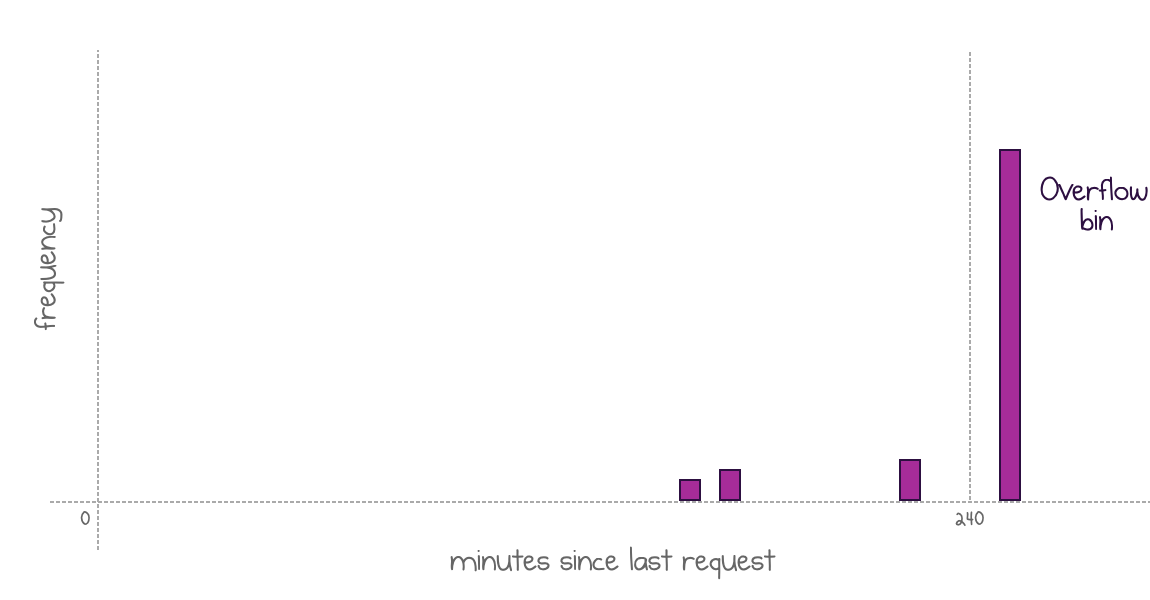
Values beyond the 4-hour limit end up in a special "everything else" overflow bin
If a lot of values start to fall into that range, the bin-based policy can’t perform well anymore. For this category of applications, the paper suggests switching to time-series analysis to predict the next interval duration. They mention the autoregressive integrated moving average model without providing many details.
As invocations of this type are infrequent, the overall overhead of such a model would stay relatively low.
Evaluation
The authors evaluated the policy based on recorded production usage statistics. The evaluation consists of two parts:
- A simulation that iterates through the data, calculates the policy models, and evaluates whether each invocation would yield a cold starts with the new policy.
- A replay of the recorded invocation trace on a modified version of Apache OpenWhisk, an open-source FaaS platform. The controller was modified to use the new policy while managing workers. The trace was scaled down by randomly selecting applications with mid-range popularity.
Both parts showed similarly promising results of reducing the cold start frequency and resource waste. The new policy reduced the average and 99-percentile function execution time 33% and 82%, respectively, while also reducing the average memory consumption of workers by 16%.
The overhead of the policy looks manageable too. The controller’s policy implementation adds less than 1 ms to the end-to-end latency and only a 5% increase in controller’s CPU utilization.
By tuning the parameters of the policy (default window, cut-off points, granularity), its implementation can achieve the same number of cold starts at much lower resource cost, or keep the same resource cost but reduce the frequency of cold starts significantly.
Production Implementation
Encouraged by the position evaluation, the team implemented the policy in Azure Functions for HTTP-triggered applications, it will be rolling out to production in stages starting this month (June 2020).
Here are some implementation details:
- Each histogram contains data for 4 hours, filling up 960 bytes per application.
- The histogram is stored in memory and backed up to a database once per hour.
- A new histogram is started every day with a history of previous values stored for two weeks.
- Worker warming is scheduled for the calculated head cut-off point minus 90 seconds.
- Pre-warming loads function dependencies and performs JIT where possible.
- All policy decisions are asynchronous, off the critical path to minimize the latency impact on the invocation.
I look forward to testing this new policy once it’s rolled out. Expect a follow-up blog post!
Open Questions
Everything above is my summary of the “Serverless in the Wild” paper’s ideas and findings. I want to close the blog post with some questions that I still have, personally.
Whether true in practice or not, the public opinion strongly perceives cold starts as a notable obstacle to serverless adoption. It’s great to see some concrete suggestions driven by data that may improve cold starts in serverless functions.
The sweet spot of the suggested policy is applications with relatively regular intervals between invocations below several hours. I think the practical effect of the strategy might still be limited. Here are some concerns that I see.
The authors reviewed my questions and provided their answers, which I’m including in the text below.
Who benefits?
Not every serverless function is sensitive to cold starts.
The policy favors functions with predictable intervals. Timer-based schedules (whether functions with timer trigger or external timers sending requests to the app or IoT devices communicating periodically) may produce perfect histograms. And yet, those functions are not damaged by a cold start and may entirely live with it.
On the other side, human-initiated requests that care about cold starts are likely to be less predictable. Does it mean they don’t enjoy much improvement with the new policy?
The Azure Functions team is rolling the policy out for HTTP functions, so they do expect it to be useful. We will know soon!
Response from the authors:
There is a large fraction of the applications that will likely benefit. Because for many applications the keep-alive interval can drastically reduce, the provider can afford to increase the keep-alive for other applications. About 50% of the applications have average inter-invocation times of 30 minutes of more. These incur many cold starts in the fixed policy, and will likely see a reduction in cold starts because their keep-alive intervals will be able to grow. Applications with idle times longer than 4 hours can also benefit because of the ARIMA time-series prediction.
Is it flexible enough?
The policy assumes that the interval distribution is stable over time. How will this hold in practice over more extended periods?
Imagine an application that is only used during business hours. Or, an application that is mostly idle but is sporadically applied for a specific business process. Or, a demo app that you want to show to your colleagues during a planning meeting. Likely, all of them would still hit cold starts at the beginning of a session.
Maybe that’s why the production implementation begins with a clean histogram every day. They will watch and learn, and may use data for the last two weeks to improve later on.
Response from the authors:
The policy does not have to assume a stationary distribution of arrival patterns. In the traces analyzed in the paper there was not a significant enough variation in the distributions to enable a deep investigation. With the production deployment, we will investigate different policies to decay information from previous histograms.
What about function warming?
There’s the elephant in the room of cold starts: function “warming”. Warming is a trick when a developer adds an extra timer-based function to their Function App so that the timer triggers every few minutes. This way, the runtime would never unload it, and an instance would always be ready.
I suspect that this simple trick still outperforms the suggested histogram-based policy in terms of cold-start prevention. Obviously, it doesn’t help the cloud provider to save costs.
Is there a way to combine two approaches and get the benefits of both?
Response from the authors:
The results in the paper take into account user-generated warm-up functions that are present in the data. If the hybrid policy is successful in preventing cold starts, there will be no need for users to create periodic warm-up functions, which represent extra effort and higher costs.
What about the scale-out cold start?
The paper focuses on applications that are invoked rarely. However, even applications with higher utilization may still hit cold starts when scaled out on multiple instances. Every new instance would need to boot, and the requests would still be waiting.
The suggested policy does not address cold starts beyond the first instance, even though they do occur and potentially have a more significant impact on latency percentiles of real-world human-facing applications.
Response from the authors:
We didn’t address scale-out cold starts in the paper. We can pre-warm the scale-out instances by forcing the scale out to happen slightly before it normally would. For example, when the scale out is triggered by a threshold number of concurrent invocations, we can lower the threshold slightly. We will be experimenting with such techniques in our implementation in Azure Functions.
Conclusion
Despite several open questions above, I’m delighted that the paper was published. I welcome any structured effort that focuses on cold start optimization. The paper highlights usage statistics, the challenges of the cold start problem, and suggests several improvements.
It’s even more exciting to see the finding being applied in Azure in production!
If you want to learn more, you can read the full paper here: Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider.

Responses