SQL Server
Event Sourcing: Optimizing NEventStore SQL read performance
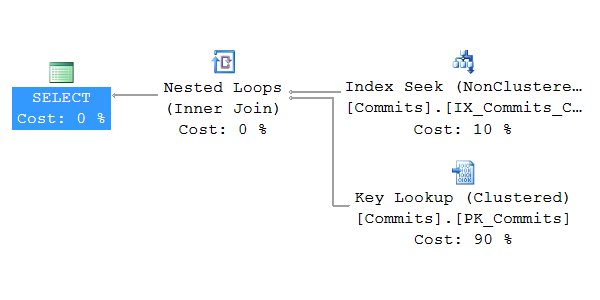
In my previous post about Event Store read complexity I described how the growth of reads from the event database might be quadratic in respect to amount of events per aggregate.
Read more...T-SQL MERGE statement is underrated
How many times did you write a SQL to save a row without knowing whether the same primary key already exists or not? You just get an object in your data access layer and you want to save all fields into the database.
Read more...