A Practical Approach to Temporal Architecture
Temporal enables developers to build highly reliable applications without having to worry about all the edge cases. If you are new to Temporal, check out my article Open Source Workflows as Code. Now that you’re excited, I’ll cover how you can get up and running with Temporal.
Temporal consists of several components. In this post, I want to outline the primary building blocks and their interactions. By the end, you’ll have a broad picture of Temporal and the considerations of deploying to development, staging, and production environments.
Workers
Workers are compute nodes that run your Temporal application code. You compile your workflows and activities into a worker executable. Next you can run the worker executable in the background and it will listen for new tasks to process.
Your first development environment will probably only need one worker that runs both workflows and activities in a single process. The worker can be hosted anywhere you wish: as a local process on your laptop, as an AWS Fargate task, as a pod in Kubernetes, and so on.
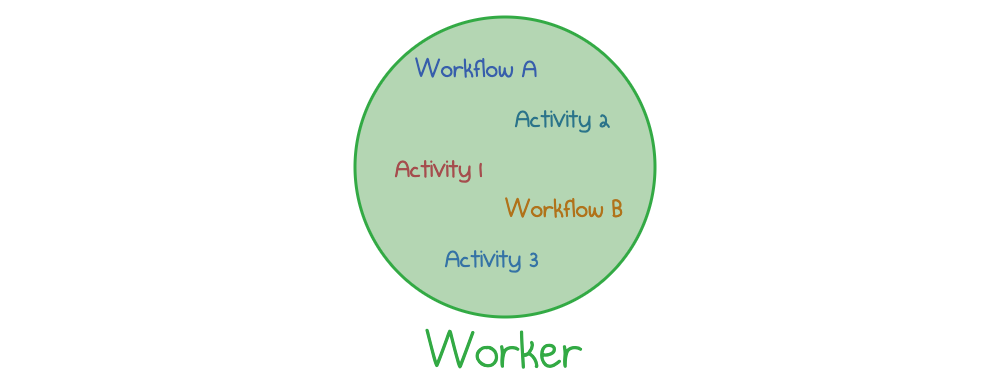
A Temporal worker executes workflows and activities
Production deployments typically run numerous workflows with significant load, so you will likely need to run multiple workers in parallel. Ensuring that nodes are spread out over a compute cluster enables resiliency and scalability.
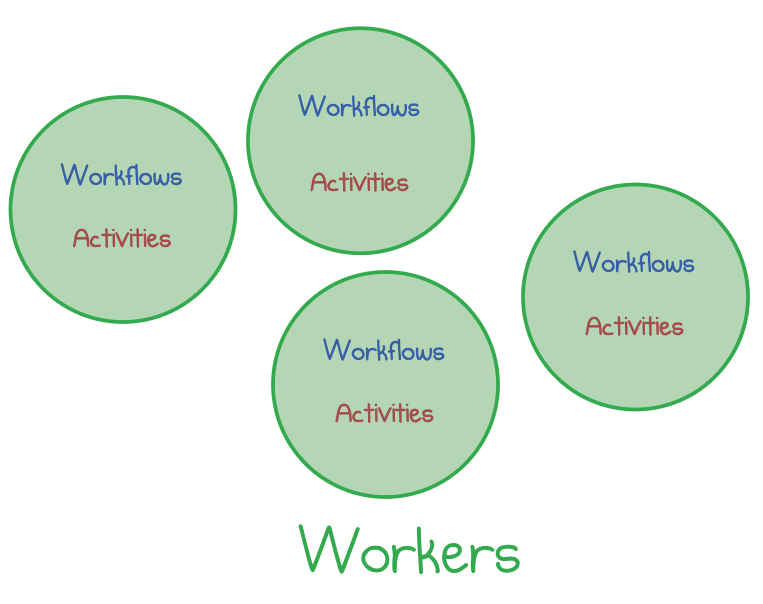
Workload scaled out to several Temporal workers
Workers operate independently, each crunching through its share of the workload. Workers are logically “stateless”: they don’t keep track of the past and future. Workers don’t talk to each other directly, but they coordinate via a central Temporal service—the brain of the system.
Temporal Service
Temporal Service is a component provided by Temporal. Its purpose is to keep track of workflows, activities, and tasks and coordinate workers’ execution.
Your early environments may have a single Service instance running in the background. A worker knows the Service’s domain name (IP) and port and connects to the Service via gRPC.
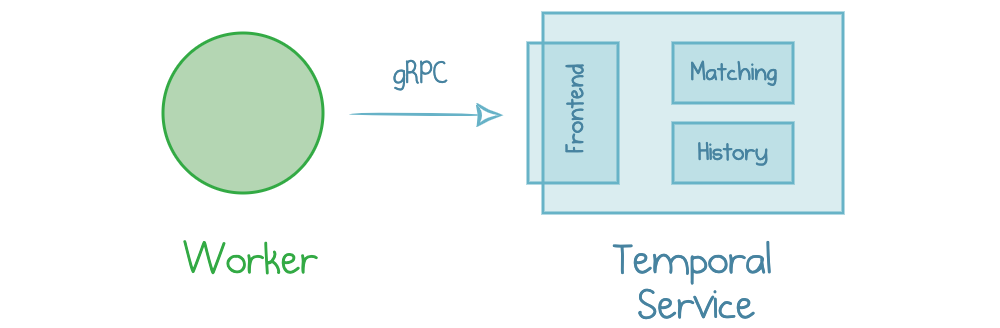
Worker interacting with Temporal Service
Temporal Service itself consists of multiple components: a front-end, matching, history, and others. However, it’s okay to treat it as a black-box “Service” for now.
Once you start growing your workloads, you will need to scale the Service components out to multiple instances for high resilience and throughput. So, several workers are now talking to several service instances.
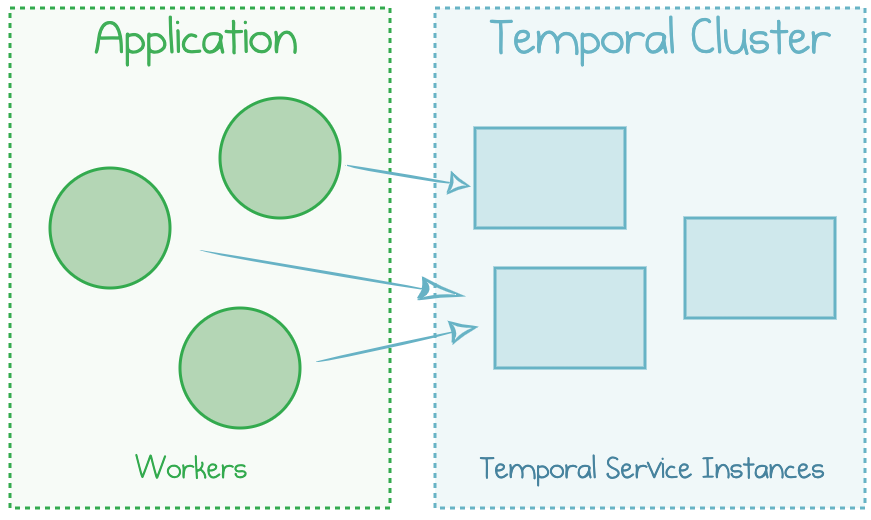
Temporal Cluster running multiple components
Temporal Service can tolerate node failures because it stores its state in an external storage.
Data Store
All the workflow data—task queues, execution state, activity logs—are stored in a persistent Data Store. Persistence technology is pluggable with two options currently officially supported: Cassandra and MySQL. More alternatives, including PostgreSQL, are on the way.
A MySQL database completes the simplest Temporal deployment diagram.
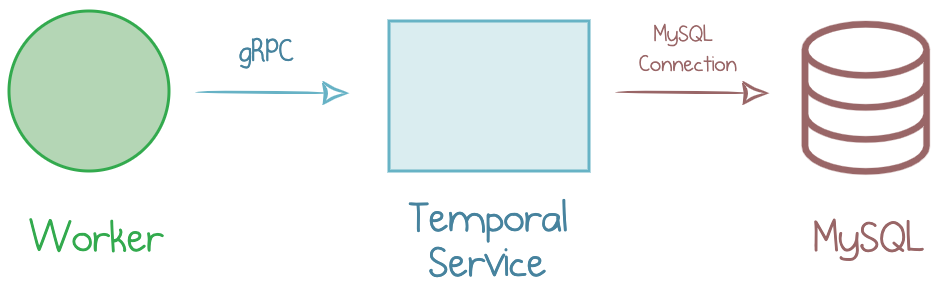
MySQL as a Data Store for Temporal
For heavily distributed applications that experience high load, it may be better to use Cassandra instead. This database could be a cluster managed by yourself or a managed cloud service (like Azure Cosmos DB):
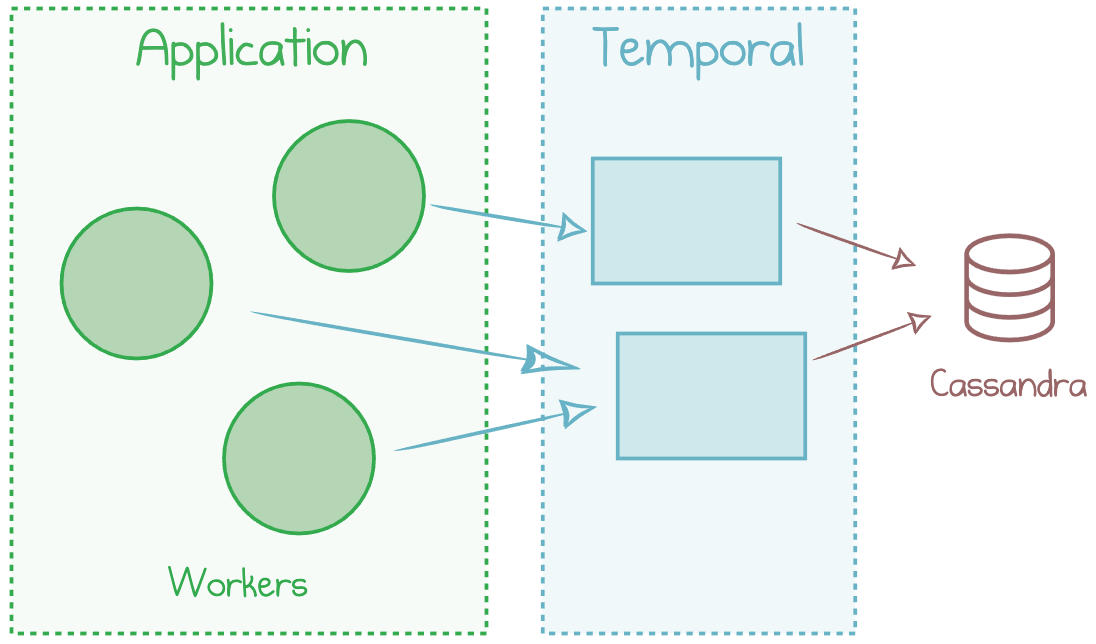
Cassandra as a Data Store for Temporal
Your code never interacts with the Data Store directly. Basically, it’s a (rather important) implementation detail of the Temporal Service.
Temporal Web Console
Temporal provides a handy web console to view namespaces, workflows, and activity history. Technically, it’s not a required component—but you probably want to have it under your belt for manual inspection and troubleshooting.
You’ll likely have other client components, for instance, to start workflow executions.
External Client
You need a client to start your very first workflow execution. It can be the Temporal command-line interface tctl or any custom code that you wrote with a call to initiate a workflow using an SDK or raw gRPC.
Each client must connect to a Temporal Service in order to start or terminate workflows, wait for completion, list the results from the history, and so on. For instance, a web application could start a workflow execution every time it handles a particular HTTP endpoint.
Put It All Together
The following picture puts all the pieces covered above together.
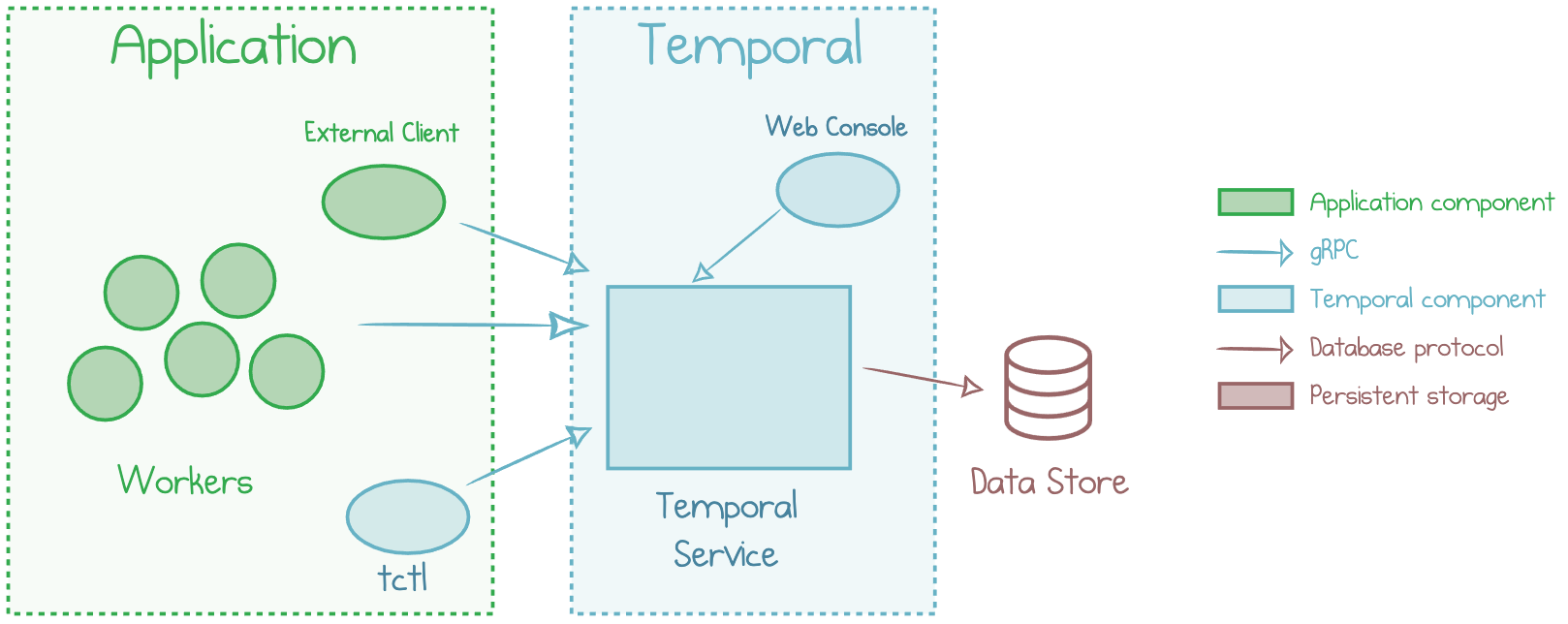
High-level Temporal architecture
As you can tell, there are quite a few components that go into making Temporal tick! Temporal is designed to handle millions of workflows reliably with high-performance guarantees while being open-source and portable across different infrastructure options. This dictates the usage of a multi-tier approach.
You can deploy everything to your development machine with the getting started guide. After that, you can start moving the components to your favorite cloud environment. Over the next weeks, I’ll be working through automation scenarios and accompanying blog posts to help you manage typical deployment needs.

Responses