From 0 to 1000 Instances: How Serverless Providers Scale Queue Processing

Whenever I see a “Getting Started with Function-as-a-Service” tutorial, it usually shows off a synchronous HTTP-triggered scenario. In my projects, though, I use a lot of asynchronous functions triggered by a queue or an event stream.
Quite often, the number of messages passing through a queue isn’t uniform over time. I might drop batches of work now and then. My app may get piles of queue items arriving from upstream systems that were down or under maintenance for an extended period. The system might see some rush-hour peaks every day or only a few busy days per month.
This is where serverless tech shines: You pay per execution, and then the promise is that the provider takes care of scaling up or down for you. Today, I want to put this scalability under test.
The goal of this article is to explore queue-triggered serverless functions and hopefully distill some practical advice regarding asynchronous functions for real projects. I will be evaluating the problem:
- Across Big-3 cloud providers (Amazon, Microsoft, Google)
- For different types of workloads
- For different performance tiers
Let’s see how I did that and what the outcome was.
DISCLAIMER. Performance testing is hard. I might be missing some crucial factors and parameters that influence the outcome. My interpretation might be wrong. The results might change over time. If you happen to know a way to improve my tests, please let me know, and I will re-run them and re-publish the results.
Methodology
In this article I analyze the execution results of the following cloud services:
- AWS Lambda triggered via SQS queues
- Azure Function triggered via Storage queues
- Google Cloud Function triggered via Cloud Pub/Sub
All functions are implemented in Javascript and are running on GA runtime.
At the beginning of each test, I threw 100,000 messages into a queue that was previously idle. Enqueuing never took longer than one minute (I sent the messages from multiple clients in parallel).
I disabled any batch processing, so each message was consumed by a separate function invocation.
I then analyzed the logs (AWS CloudWatch, Azure Application Insights, and GCP Stackdriver Logging) to generate charts of execution distribution over time.
How Scaling Actually Works
To understand the experiment better, let’s look at a very simplistic but still useful model of how cloud providers scale serverless applications.
All providers handle the increased load by scaling out, i.e., by creating multiple instances of the same application that execute the chunks of work in parallel.
In theory, a cloud provider could spin up an instance for each message in the queue as soon as the messages arrive. The backlog processing time would then stay very close to zero.
In practice, allocating instances is not cheap. The Cloud provider has to boot up the function runtime, hit a cold start, and waste expensive resources on a job that potentially will take just a few milliseconds.
So the providers are trying to find a sweet spot between handling the work as soon as possible and using resources efficiently. The outcomes differ, which is the point of my article.
AWS
AWS Lambda defines scale out with a notion of Concurrent Executions. Each instance of your AWS Lambda is handling a single execution at any given time. In our case, it’s processing a single SQS message.
It’s helpful to think of a function instance as a container working on a single task. If execution pauses or waits for an external I/O operation, the instance is on hold.
The model of concurrent executions is universal to all trigger types supported by Lambdas. An instance doesn’t work with event sources directly; it just receives an event to work on.
There is a central element in the system, let’s call it “Orchestrator”. The Orchestrator is the component talking to an SQS queue and getting the messages from it. It’s then the job of the Orchestrator and related infrastructure to provision the required number of instances for working on concurrent executions:
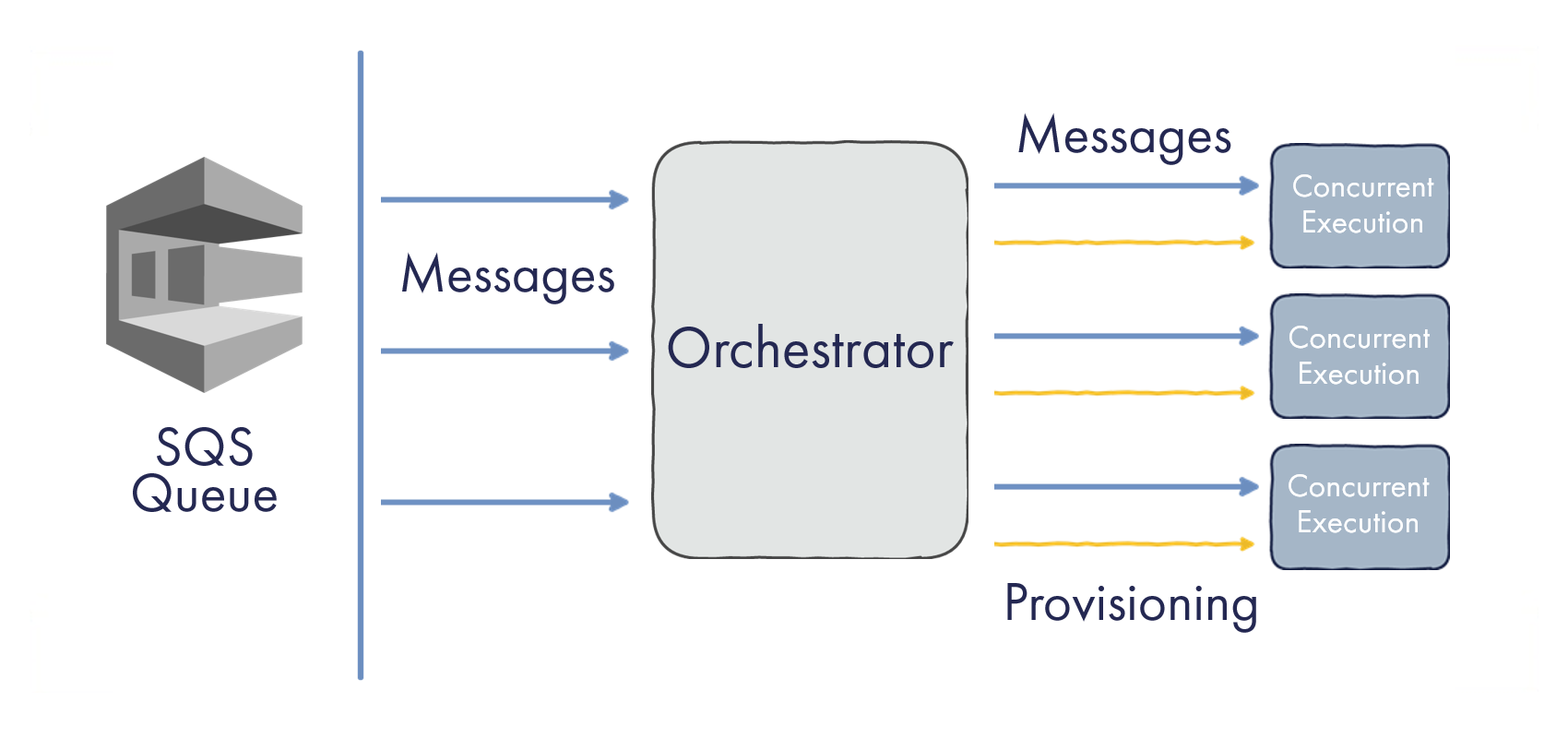
Model of AWS Lambda Scale-Out
As to scaling behavior, here is what the official AWS docs say:
AWS Lambda automatically scales up … until the number of concurrent function executions reaches 1000 … Amazon Simple Queue Service supports an initial burst of 5 concurrent function invocations and increases concurrency by 60 concurrent invocations per minute.
GCP
The model of Google Cloud Functions is very similar to what AWS does. It runs a single simultaneous execution per instance and routes the messages centrally.
I wasn’t able to find any scaling specifics except the definition of Function Quotas.
Azure
Experiments with Azure Functions were run on Consumption Plan —the dynamically scaled and billed-per-execution runtime. The concurrency model of Azure Functions is different from the counterparts of AWS/GCP.
Function App instance is closer to a VM than a single-task container. It runs multiple concurrent executions in parallel. Equally importantly, it pulls messages from the queue on its own instead of getting them pushed from a central Orchestrator.
There is still a central coordinator called Scale Controller, but its role is a bit more subtle. It connects to the same data source (the queue) and needs to determine how many instances to provision based on the metrics from that queue:
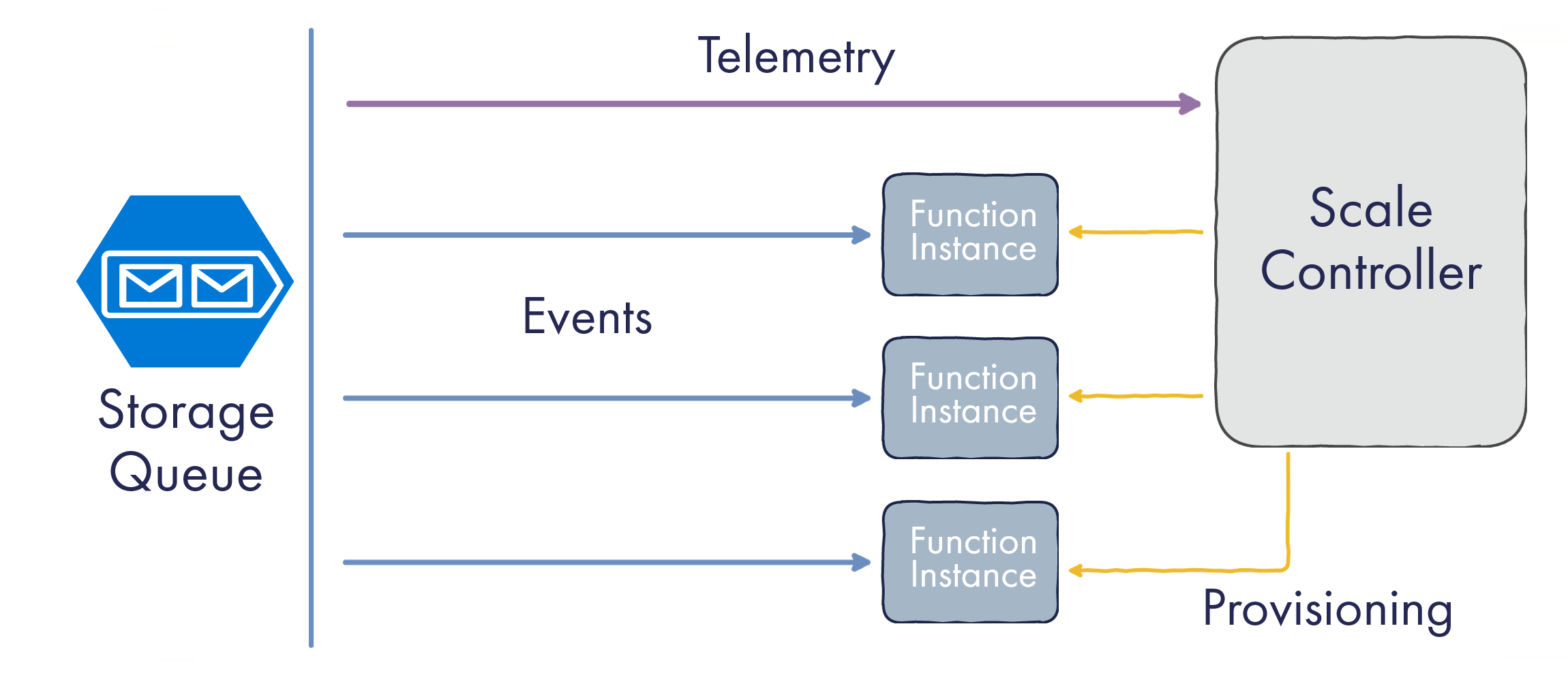
Model of Azure Function Scale-Out
This model has pros and cons. If one execution is idle, waiting for some I/O operation such as an HTTP request to finish, the instance might become busy processing other messages, thus being more efficient. Running multiple executions is useful in terms of shared resource utilization, e.g., keeping database connection pools and reusing HTTP connections.
On the flip side, the Scale Controller now needs to be smarter: to know not only the queue backlog but also how instances are doing and at what pace they are processing the messages. It’s probably achievable based on queue telemetry though.
Let’s start applying this knowledge in practical experiments.
Pause-the-World Workload
My first serverless function is aimed to simulate I/O-bound workloads without using external dependencies to keep the experiment clean. Therefore, the implementation is extremely straightforward: pause for 500 ms and return.
It could be loading data from a scalable third-party API. It could be running a database query.
Instead, it just runs setTimeout.
I sent 100k messages to queues of all three cloud providers and observed the result.
AWS
AWS Lambda allows multiple instance sizes to be provisioned. Since the workload is neither CPU- nor memory-intensive, I was using the smallest memory allocation of 128 MB.
Here comes the first chart of many, so let’s learn to read it. The horizontal axis shows time in minutes since all the messages were sent to the queue.
The line going from top-left to bottom-right shows the decreasing queue backlog. Accordingly, the left vertical axis denotes the number of items still-to-be-handled.
The bars show the number of concurrent executions crunching the messages at a given time. Every execution logs the instance ID so that I could derive the instance count from the logs. The right vertical axis shows the instance number.
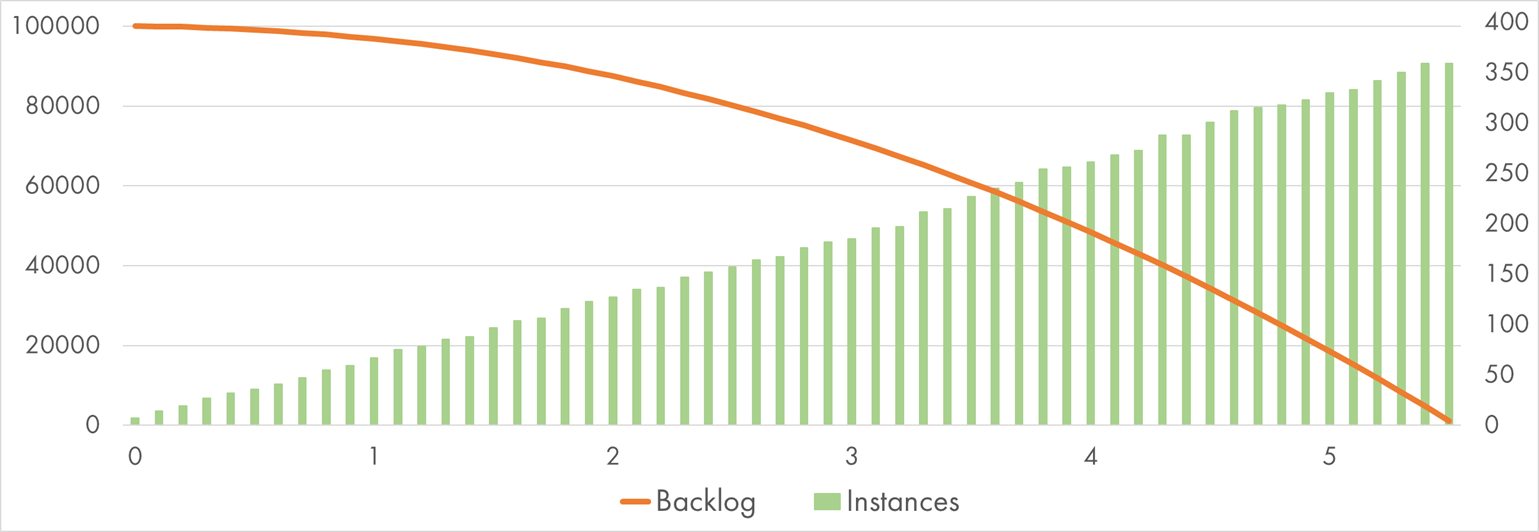
AWS Lambda processing 100k SQS messages with "Pause" handler
It took AWS Lambda 5.5 minutes to process the whole batch of 100k messages. For comparison, the same batch processed sequentially would take about 14 hours.
Notice how linear the growth of instance count is. If I apply the official scaling formula:
Instance Count = 5 + Minutes * 60 = 5 + 5.5 * 60 = 335
We get a very close result! Promises kept.
GCP
Same function, same chart, same instance size of 128 MB of RAM—but this time for Google Cloud Functions:
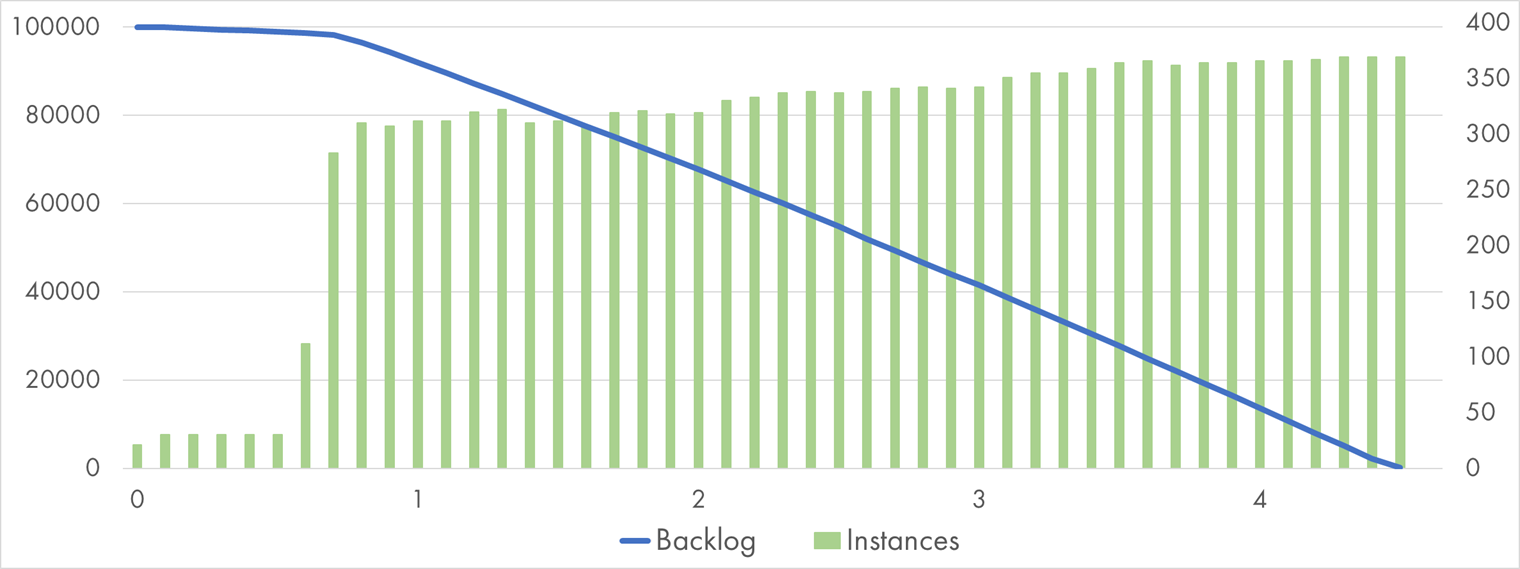
Google Cloud Function processing 100k Pub/Sub messages with "Pause" handler
Coincidentally, the total amount of instances, in the end, was very close to AWS. The scaling pattern looks entirely different though: Within the very first minute, there was a burst of scaling close to 300 instances, and then the growth got very modest.
Thanks to this initial jump, GCP managed to finish processing almost one minute earlier than AWS.
Azure
Azure Function doesn’t have a configuration for allocated memory or any other instance size parameters.
The shape of the chart for Azure Functions is very similar, but the instance number growth is significantly different:
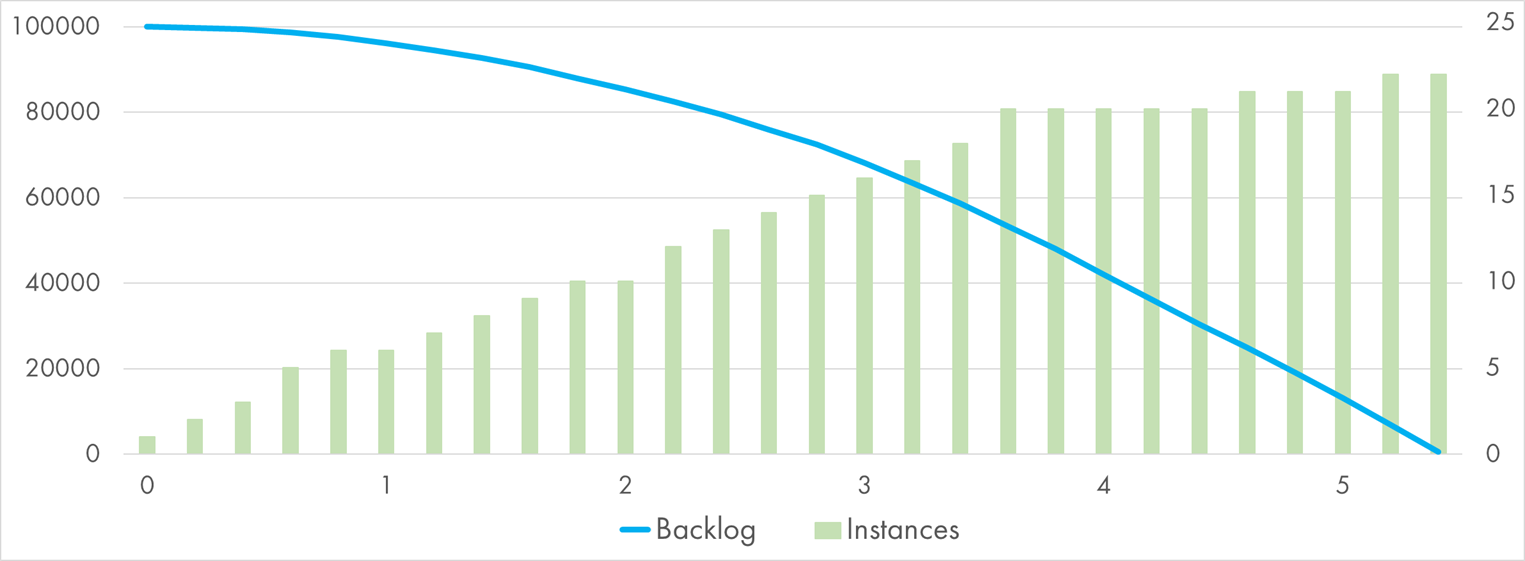
Azure Function processing 100k queue messages with "Pause" handler
The total processing time was a bit faster than AWS and somewhat slower than GCP. Azure Function instances process several messages in parallel, so it takes much less of them to do the same amount of work.
Instance number growth seems far more linear than bursty.
What we learned
Based on this simple test, it’s hard to say if one cloud provider handles scale-out better than the others.
It looks like all serverless platforms under stress are making decisions at the resolution of 5-15 seconds, so the backlog processing delays are likely to be measured in minutes. It sounds quite far from the theoretical “close to zero” target but is most likely good enough for the majority of applications.
Crunching Numbers
That was an easy job though. Let’s give cloud providers a hard time by executing CPU-heavy workloads and see if they survive!
This time, each message handler calculates a Bcrypt hash with a cost of 10. One such calculation takes about 200 ms on my laptop.
AWS
Once again, I sent 100k messages to an SQS queue and recorded the processing speed and instance count.
Since the workload is CPU-bound, and AWS allocates CPU shares proportionally to the allocated memory, the instance size might have a significant influence on the result.
I started with the smallest memory allocation of 128 MB:
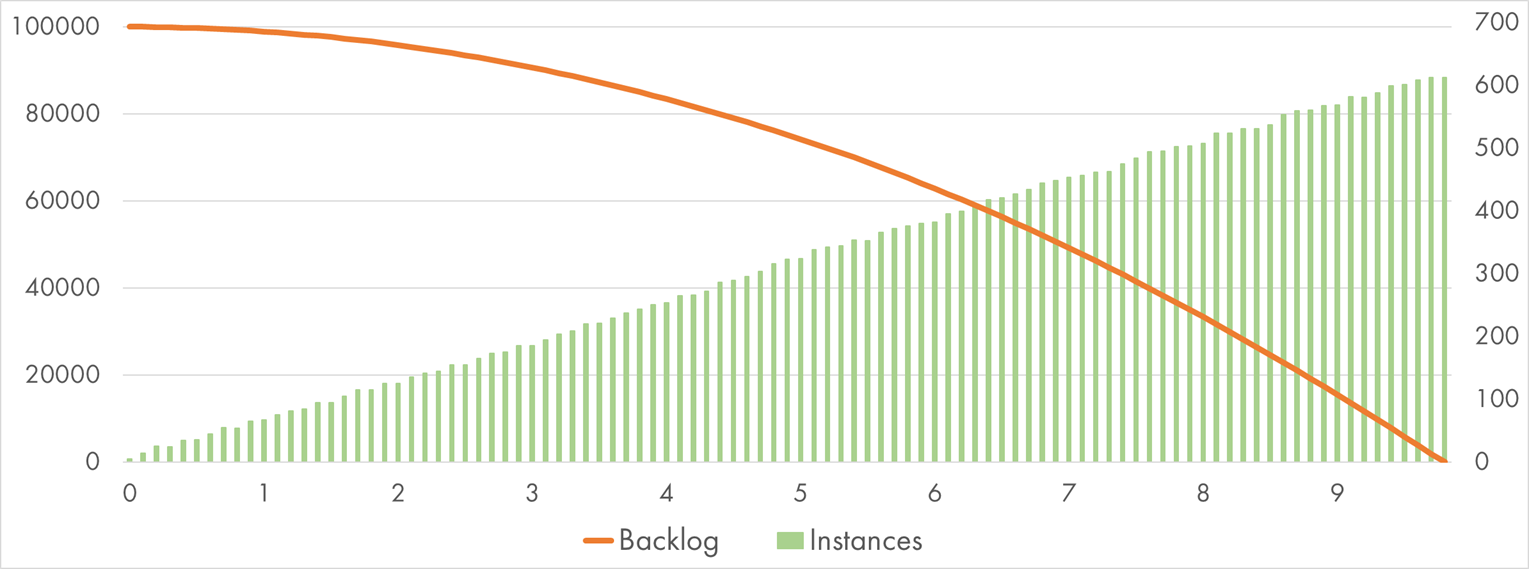
AWS Lambda (128 MB) processing 100k SQS messages with "Bcrypt" handler
This time it took almost 10 minutes to complete the experiment.
The scaling shape is pretty much the same as last time, still correctly described by the formula
60 * Minutes + 5. However, because AWS allocates a small fraction of a full CPU to each 128 MB
execution, one message takes around 1,700 ms to complete. Thus, the total work increased
approximately by the factor of 3 (47 hours if done sequentially).
At the peak, 612 concurrent executions were running, nearly double the amount in our initial experiment. So, the total processing time increased only by the factor of 2—up to 10 minutes.
Let’s see if larger Lambda instances would improve the outcome. Here is the chart for 512 MB of allocated memory:
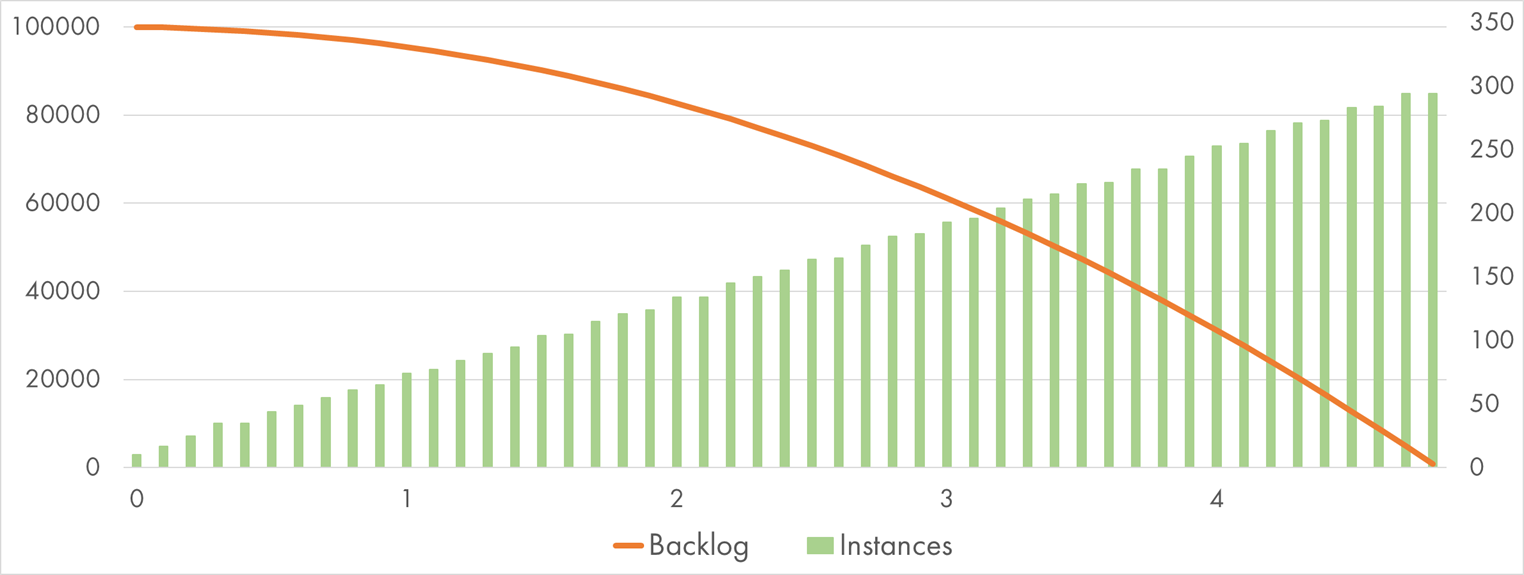
AWS Lambda (512 MB) processing 100k SQS messages with "Bcrypt" handler
And yes it does. The average execution duration is down to 400 ms: 4 times less, as expected. The scaling shape still holds, so the entire batch was done in less than four minutes.
GCP
I executed the same experiment on Google Cloud Functions. I started with 128 MB, and it looks impressive:
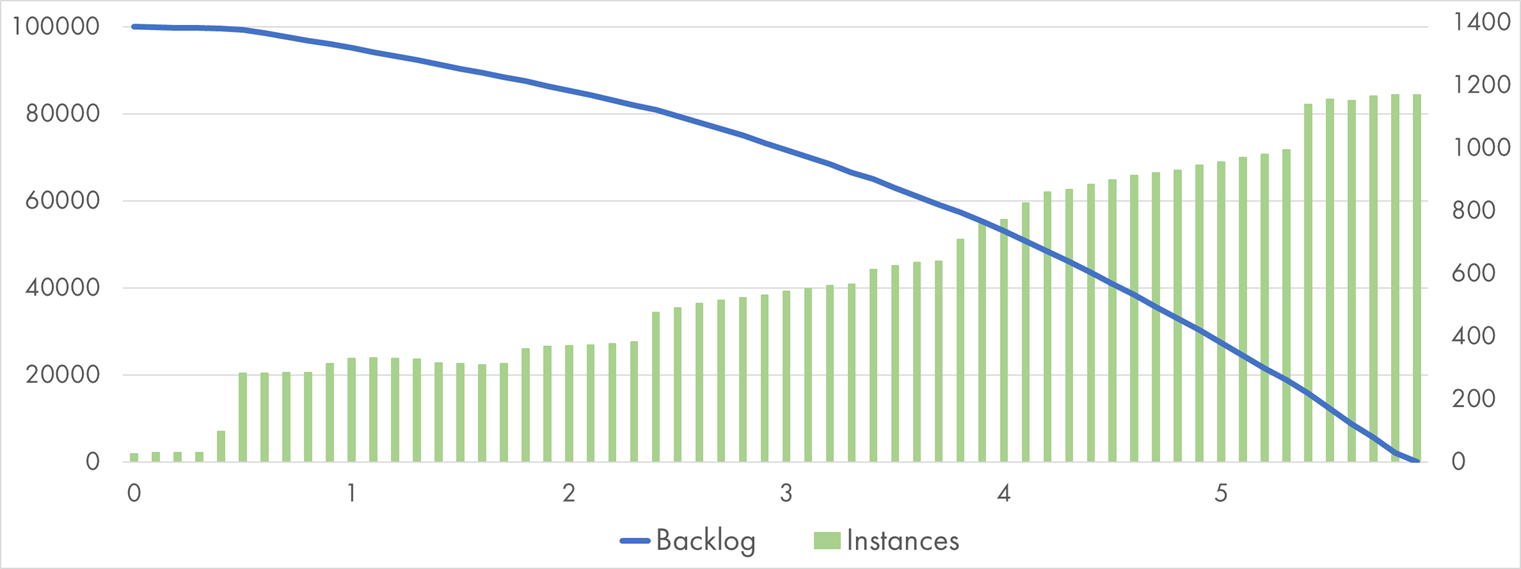
Google Cloud Function (128 MB) processing 100k Pub/Sub messages with "Bcrypt" handler
The average execution duration is very close to Amazon’s: 1,600 ms. However, GCP scaled more aggressively—to a staggering 1,169 parallel executions! Scaling also has a different shape: It’s not linear but grows in steep jumps. As a result, it took less than six minutes on the lowest CPU profile—very close to AWS’s time on a 4x more powerful CPU.
What will GCP achieve on a faster CPU? Let’s provision 512 MB. It must absolutely crush the test. Umm, wait, look at that:
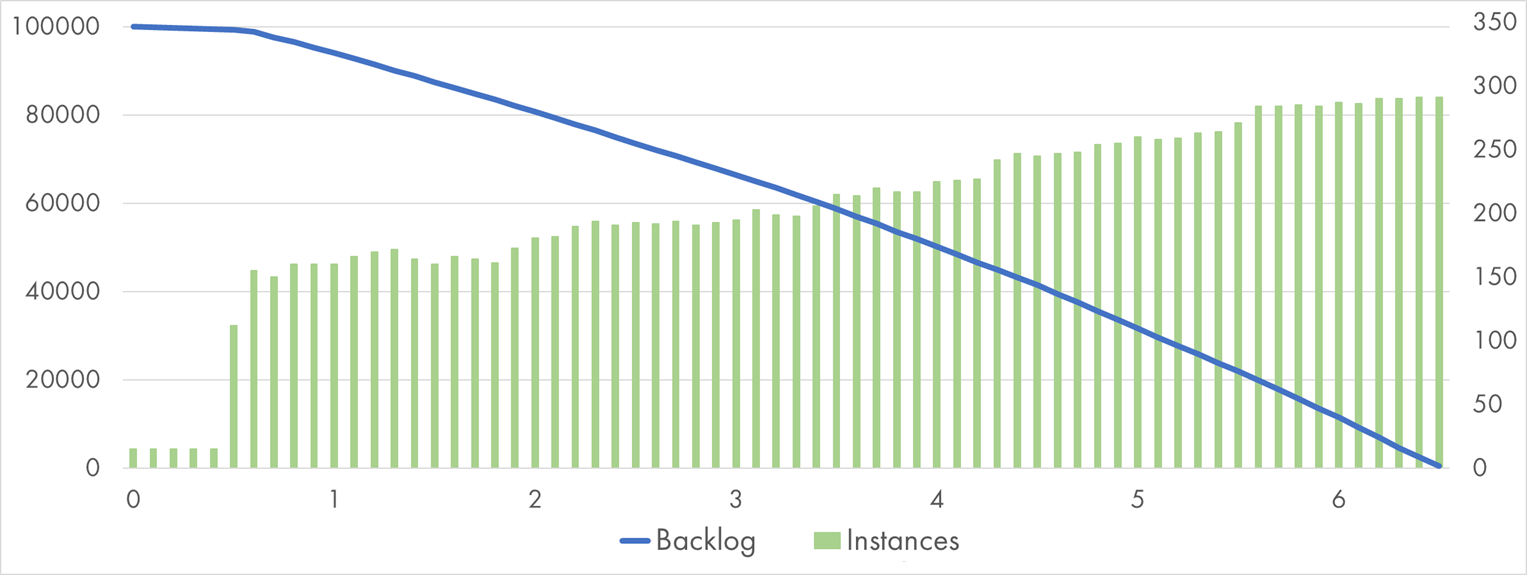
Google Cloud Function (512 MB) processing 100k Pub/Sub messages with "Bcrypt" handler
It actually… got slower. Yes, the average execution time is 4x lower: 400 ms, but the scaling got much less aggressive too, which canceled the speedup.
I confirmed it with the largest instance size of 2,048 MB:
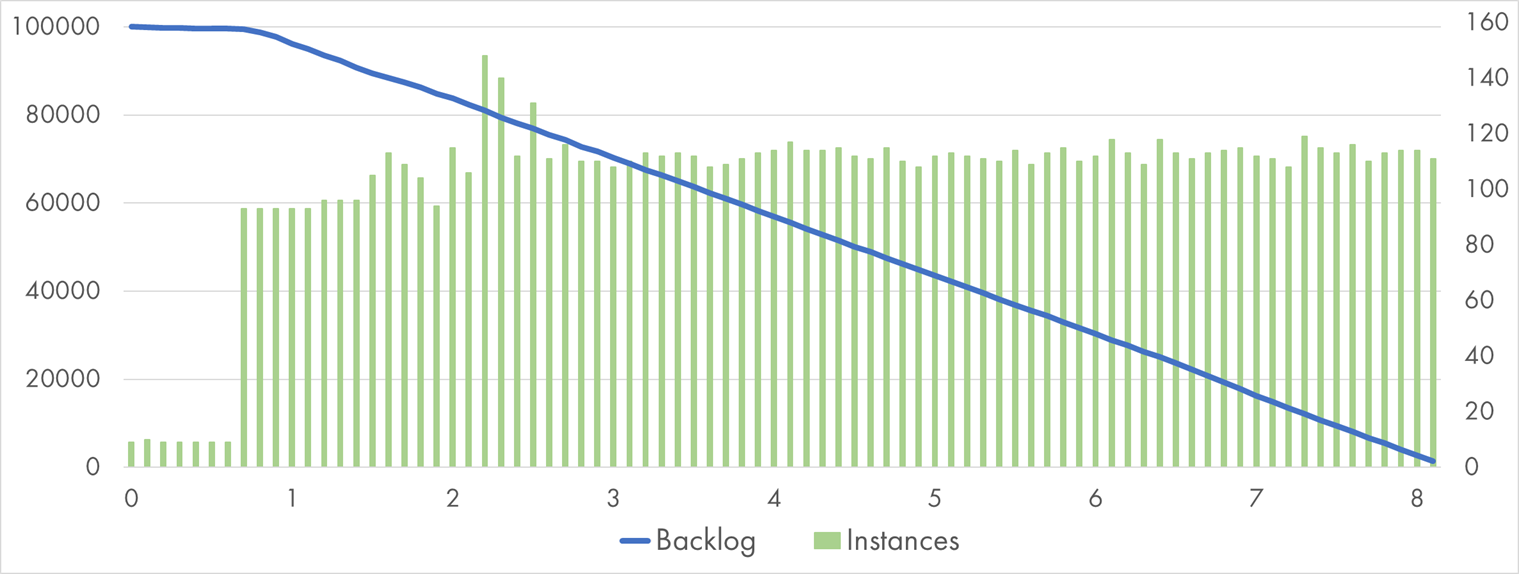
Google Cloud Function (2 GB) processing 100k Pub/Sub messages with "Bcrypt" handler
CPU is fast: 160 ms average execution time, but the total time to process 100k messages went up to eight minutes. Beyond the initial spike at the first minute, it failed to scale up any further and stayed at about 110 concurrent executions.
It seems that GCP is not that keen to scale out larger instances. It’s probably easier to find many small instances available on the pool rather than a similar number of giant instances.
Azure
A single invocation takes about 400 ms to complete on Azure Function. Here is the burndown chart:
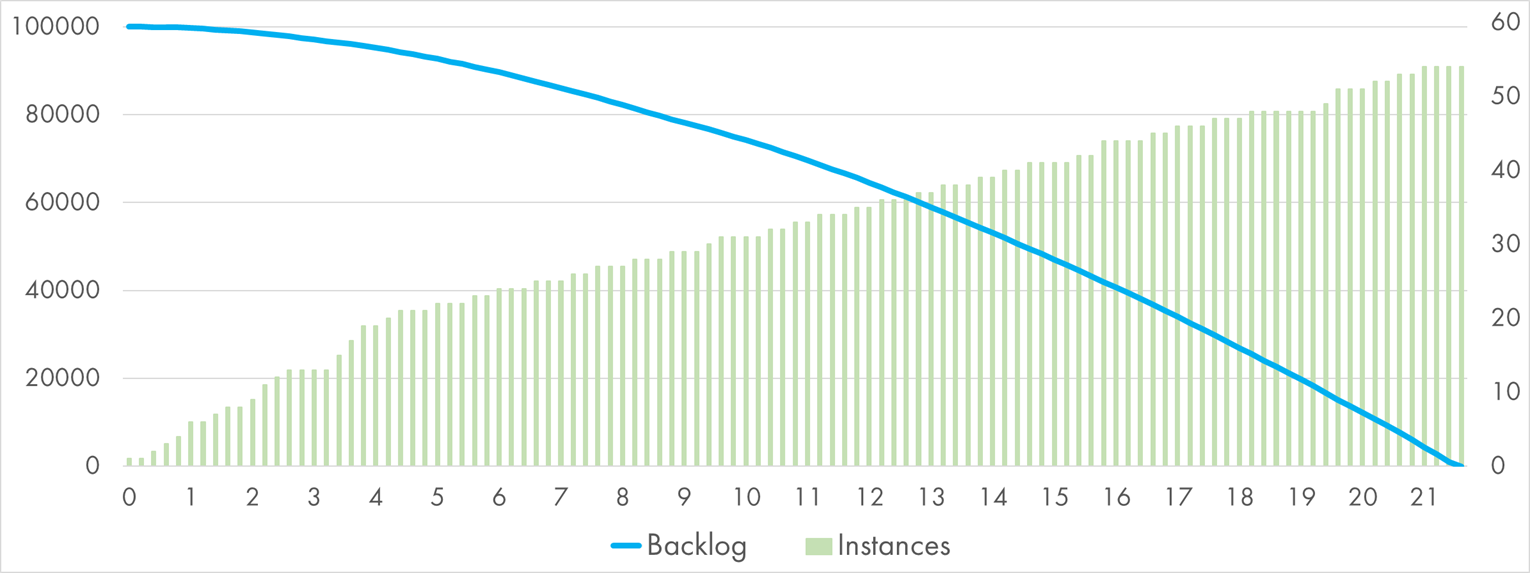
Azure Function processing 100k queue messages with "Bcrypt" handler
Azure spent 21 minutes to process the whole backlog. The scaling was linear, similarly to AWS,
but with a much slower pace regarding instance size growth, about 2.5 * Minutes.
As a reminder, each instance could process multiple queue messages in parallel, but each such execution would be competing for the same CPU resource, which doesn’t help for the purely CPU-bound workload.
Practical Considerations
Time for some conclusions and pieces of advice to apply in real serverless applications.
Serverless is great for async data processing
If you are already using cloud services, such as managed queues and topics, serverless functions are the easiest way to consume them.
Moreover, the scalability is there too. When was the last time you ran 1,200 copies of your application?
Serverless is not infinitely scalable
There are limits. Your functions won’t scale perfectly to accommodate your spike—a provider-specific algorithm will determine the scaling pattern.
If you have large spikes in queue workloads, which is quite likely for medium- to high-load scenarios, you can and should expect delays up to several minutes before the backlog is fully digested.
All cloud providers have quotas and limits that define an upper boundary of scalability.
Cloud providers have different implementations
AWS Lambda seems to have a very consistent and well-documented linear scale growth for SQS-triggered Lambda functions. It will happily scale to 1,000 instances, or whatever other limit you hit first.
Google Cloud Functions has the most aggressive scale-out strategy for the smallest instance sizes. It can be a cost-efficient and scalable way to run your queue-based workloads. Larger instances seem to scale in a more limited way, so a further investigation is required if you need those.
Azure Functions share instances for multiple concurrent executions, which works better for I/O-bound workloads than for CPU-bound ones. Depending on the exact scenario that you have, it might help to play with instance-level settings.
Don’t forget batching
For the tests, I was handling queue messages in the 1-by-1 fashion. In practice, it helps if you can batch several messages together and execute a single action for all of them in one go.
If the destination for your data supports batched operations, the throughput will usually increase immensely. Processing 100,000 Events Per Second on Azure Functions is an excellent case to prove the point.
You might get too much scale
A month ago, Troy Hunt published a great post Breaking Azure Functions with Too Many Connections. His scenario looks very familiar: He uses queue-triggered Azure Functions to notify subscribers about data breaches. One day, he dropped 126 million items into the queue, and Azure scaled out, which overloaded Mozilla’s servers and caused them to go all-timeouts.
Another consideration is that non-serverless dependencies limit the scalability of your serverless application. If you call a legacy HTTP endpoint, a SQL database, or a third-party web service—be sure to test how they react when your serverless function scales out to hundreds of concurrent executions.
Stay tuned for more serverless performance goodness!
